之前介绍我的源码阅读方法,有粉丝朋友说很有帮助,认为是授人予鱼。这是过誉了,也让我很受鼓舞,这次带来另外一种阅读方法,希望对大家也有帮助。
在前文中我介绍了两种源码阅读方法:
- 概读法,对一个项目,跟随API,进行核心功能实现的阅读,跳过异常,分支等功能,快速了解项目底层实现原理
- 历史对比法,对比源码的版本修改历史,分析新增功能如何实现和扩展,分析如何修改bug。
如果说概读法可以了解一个项目是what。历史对比可以理解一段代码why这样写。这次我介绍的 慢读法 就是how。我们一行一行的去看代码,分析功能实现的所有细节。慢读法,可以学习如何编写代码,提高自己的编码水准。慢读法,需要有点耐性,尽量做到不漏过一行一字。像古代一字之师郑谷把僧人齐己的“前村深雪里,昨夜数枝开” 诗句修改成 “前村深雪里,昨夜一枝开”一样,一点一点去推敲。
本次慢读法使用的是python3.8中的xmlrpc-server部分,全文大概1000行,我们只阅读上半部分600行,大概30分钟内可以读完,时间紧张的朋友欢迎收藏了慢慢看。
- 帮助和依赖分析
- SimpleXMLRPCDispatcher分析
- SimpleXMLRPCRequestHandler分析
- SimpleXMLRPCServer 分析
- MultiPathXMLRPCServer && CGIXMLRPCRequestHandler
- rpc-doc
- 小结
帮助和依赖分析
我们常说注释是代码的一部分,xmlrpc-server中的注释很详尽,对我们学习具有指导意义。比如头部注释中,很详细的介绍了如何扩展SimpleXMLRPCServer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
4. Subclass SimpleXMLRPCServer:
class MathServer(SimpleXMLRPCServer):
def _dispatch(self, method, params):
try:
# We are forcing the 'export_' prefix on methods that are
# callable through XML-RPC to prevent potential security
# problems
func = getattr(self, 'export_' + method)
except AttributeError:
raise Exception('method "%s" is not supported' % method)
else:
return func(*params)
def export_add(self, x, y):
return x + y
server = MathServer(("localhost", 8000))
server.serve_forever()
|
MathServer方法约定对外暴露的rpc方法使用export_前缀,这个策略对服务程序管理非常有用,可以在语法层级的private和public之上增加business类型的方法。和nodejs中使用export导出函数外部接口类似。
模块依赖部分,import的try-except语句可以帮助我们更好的适配依赖:
1
2
3
4
5
|
...
try:
import fcntl
except ImportError:
fcntl = None
|
上面的代码还不太说明问题,下面例子会更直观。优先导入速度更快的simplejson, 不存在的情况下再使用默认的json:
1
2
3
4
5
|
# requests/compat.py
try:
import simplejson as json
except ImportError:
import json
|
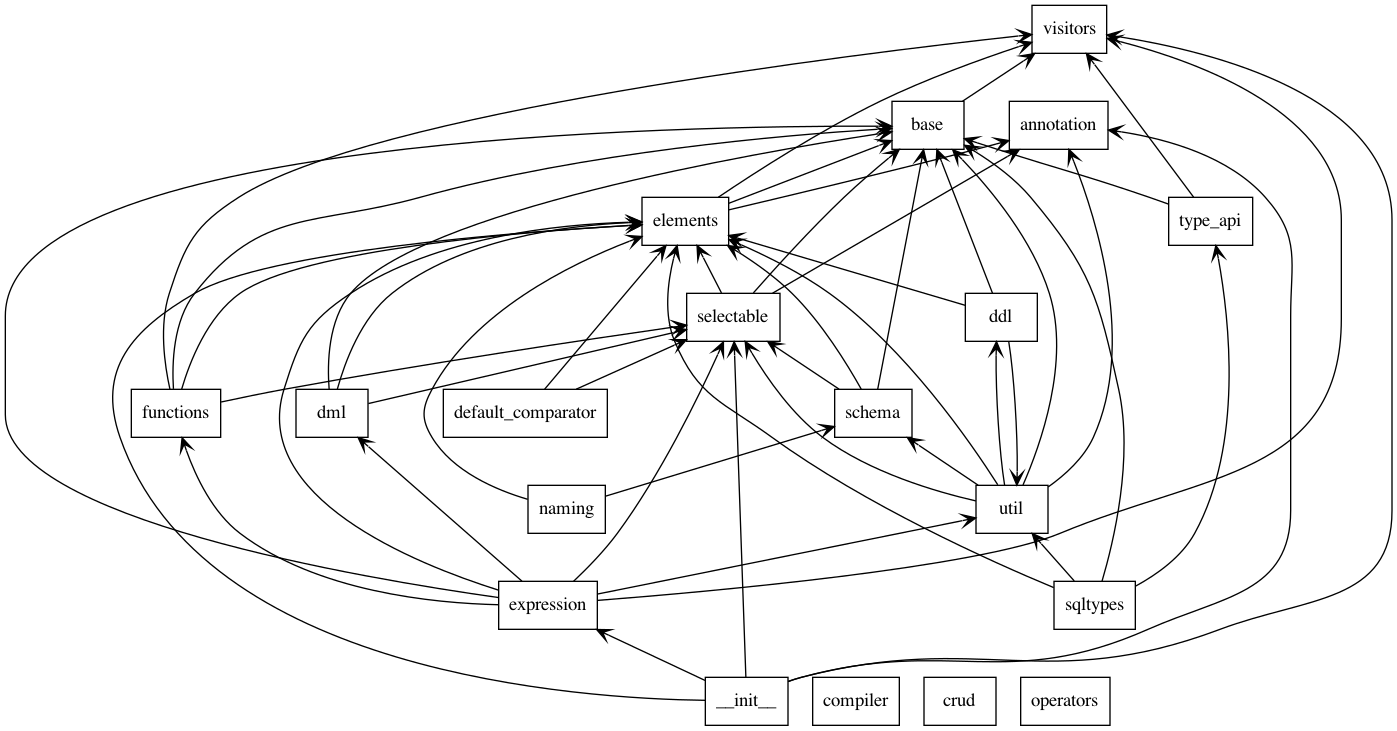
模块依赖还有一个源码阅读的小技巧:依赖越少的模块,相对容易阅读,应该最先阅读。比如下面的sqlalchemy的sql模块构成,是一个金字塔结构,阅读时候从最顶端的visitors开始更容易上手:
resolve_dotted_attribute函数链式查找对象的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def resolve_dotted_attribute(obj, attr, allow_dotted_names=True):
"""resolve_dotted_attribute(a, 'b.c.d') => a.b.c.d
Resolves a dotted attribute name to an object. Raises
an AttributeError if any attribute in the chain starts with a '_'.
If the optional allow_dotted_names argument is false, dots are not
supported and this function operates similar to getattr(obj, attr).
"""
if allow_dotted_names:
attrs = attr.split('.')
else:
attrs = [attr]
for i in attrs:
if i.startswith('_'):
raise AttributeError(
'attempt to access private attribute "%s"' % i
)
else:
obj = getattr(obj,i)
return obj
|
- 函数注释很清晰的介绍了功能:(a, ‘b.c.d’) => a.b.c.d, 查找a的b属性的c属性的d属性,这是一个链式调用
- 这里使用列表循环来实现递归查找,如果用递归肯定是查找a的b属性,然后把b当做参数对象再查找c…,列表循环显然更优
- 将attr处理成attrs数组,让后面的代码逻辑更清晰
- 属性查找时候遵循对象的私有属性使用
_的约定
- 异常处理,程序可以抛出
AttributeError('attempt to access private attribute "%s"' % i) 这样有自定义消息的message,帮助问题排查
list_public_methods查找对象的所有公开方法:
1
2
3
4
5
|
def list_public_methods(obj):
return [member for member in dir(obj)
if not member.startswith('_') and
callable(getattr(obj, member))]
|
- 魔法函数
dir可以列出对象所有的属性和方法;魔法函数getattr可以根据字符串名称动态获取对象的方法/属性
callable方法可以判断一个对象是不是一个方法,因为python中没有isinstance(x,function)的方法for in if语句可以对生成式根据指定条件进行过滤
SimpleXMLRPCDispatcher分析
SimpleXMLRPCDispatcher负责和xmlrpc服务的核心逻辑之一:
1
2
3
4
5
6
7
8
9
|
class SimpleXMLRPCDispatcher:
def __init__(self, allow_none=False, encoding=None,
use_builtin_types=False):
self.funcs = {}
self.instance = None
self.allow_none = allow_none
self.encoding = encoding or 'utf-8'
self.use_builtin_types = use_builtin_types
|
类定义除上面的写法外,还有一种是 class SimpleXMLRPCDispatcher(object), 我一般喜欢用这种。如果大家考古,可以发现在python2中还有新式类和旧式类的说法。在python3中都是新式类,不管使用哪种写法。
SimpleXMLRPCDispatcher的构造函数,我们可以思考下面写法的差异:
1
2
3
|
def __init__(self, allow_none=False, encoding="utf-8",
use_builtin_types=False):
self.encoding = encoding
|
encoding关键字参数,默认值是utf-8。相对来说,没有源码健壮。比如错误的传入 encoding=None 参数的时候,默认的encoding就丢失了,源码就不会存在这个问题。
构造函数中字典self.funcs = {} or self.funcs = dict() 那种更优呢?先看测试数据, 用数据说话:
1
2
3
4
5
6
7
8
9
|
# python3 -m timeit -n 1000000 -r 5 -v 'dict()'
raw times: 115 msec, 98.4 msec, 99.8 msec, 99.3 msec, 98.7 msec
1000000 loops, best of 5: 98.4 nsec per loop
# python3 -m timeit -n 1000000 -r 5 -v '{}'
raw times: 23.8 msec, 20.8 msec, 19.2 msec, 18.8 msec, 18.6 msec
1000000 loops, best of 5: 18.6 nsec per loop
|
测试可见,使用 {} 效率更高。为什么呢,我们可以查看二者的字节码对比:
1
2
3
4
5
6
7
8
|
1 0 LOAD_NAME 0 (dict)
2 CALL_FUNCTION 0
4 POP_TOP
3 6 BUILD_MAP 0
8 POP_TOP
10 LOAD_CONST 0 (None)
12 RETURN_VALUE
|
dict()实际上是一次函数调用,相对资源消耗更大。类似的还有list() vs [],所以大家初始化字典和列表都推荐使用{}和[]关键字语法。
register_instance函数用于dispatcher接受外部注册的服务对象:
1
2
3
|
def register_instance(self, instance, allow_dotted_names=False):
self.instance = instance
self.allow_dotted_names = allow_dotted_names
|
- 属性 allow_dotted_names 没有在构造函数中初始化,这个其实是不符合规范。如果我们自己的代码,IDE会有智能提示,如下图:
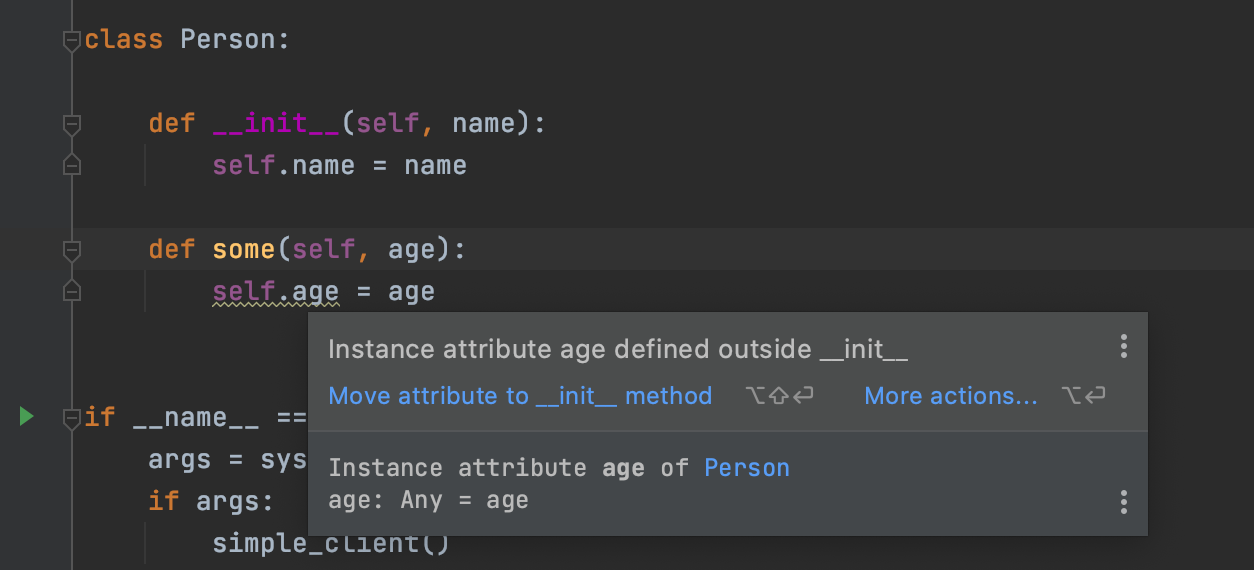
额外提一点,代码整洁就是在IDE中不出现黄色的warnings和weak warnings,绿色的typos, 当然红色的 error 更不应该出现。
register_function函数用于dispatcher接受外部注册的服务函数。和服务对象注册不一样,对象可以理解为一组函数的集合,这里是单个函数:
1
2
3
4
5
6
7
8
9
10
|
def register_function(self, function=None, name=None):
# decorator factory
if function is None:
return partial(self.register_function, name=name)
if name is None:
name = function.__name__
self.funcs[name] = function
return function
|
- functools.partial函数非常有用,可以帮助我们固定某个函数的参数,减少重复代码。
- 参数function和name先后顺序也是有讲究的。name在后,这样可以不用传name参数,使用
register_function(some_func) 把function参数当做位置参数使用。如果name在前面,则无法这样使用。
register_introspection_functions方法注册了xmlrpc-server的一些帮助信息:
1
2
3
4
|
def register_introspection_functions(self):
self.funcs.update({'system.listMethods' : self.system_listMethods,
'system.methodSignature' : self.system_methodSignature,
'system.methodHelp' : self.system_methodHelp})
|
- 注意字典的update方法,同样还有setdefault,这些都是相对其它语言比较少见的,学会了代码更pythonic
现在先跳跃一下,查看注册的几个帮助方法,先看system_listMethods:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def system_listMethods(self):
methods = set(self.funcs.keys())
if self.instance is not None:
# Instance can implement _listMethod to return a list of
# methods
if hasattr(self.instance, '_listMethods'):
methods |= set(self.instance._listMethods())
# if the instance has a _dispatch method then we
# don't have enough information to provide a list
# of methods
elif not hasattr(self.instance, '_dispatch'):
methods |= set(list_public_methods(self.instance))
return sorted(methods)
|
- 将funcs字典的key返回的可迭代对象(类型是dict_keys)转换成set,方便进行集合的集合处理
- None判断推荐
is not None而不是 if not self.instance:
- 集合求交集赋值可以使用
|=, 类似+=1
- 集合没有sort方法,不像列表有
sorted(list)和list.sort()两种方法。后者是原地排序,但是返回None;前者会重新生成一个列表。
- 动态获取属性这里使用
self.instance._listMethods(),对比一下getattr(instance, "listMethods")() , 前者更直观。
系统帮助函数使用pydoc模块获取函数的帮助文档:
1
2
3
|
def system_methodHelp(self, method_name):
...
return pydoc.getdoc(method)
|
下面是一个函数的文档实例:
1
2
3
4
5
6
7
8
9
|
def incr(self, age):
"""
长一岁
:type age: int
:rtype: int
:return 年龄+1
"""
self.age = age
return self.age
|
通过pydoc.getdoc得到的帮助信息如下,这是自动生成api文档的基础。
1
2
3
4
|
长一岁
:type age: int
:rtype: int
:return 年龄+1
|
_methodHelp展示了如何提供额外的rpc使用示例,帮助client理解API:
1
2
3
4
5
6
7
8
9
10
11
|
def _methodHelp(self, method):
# this method must be present for system.methodHelp
# to work
if method == 'add':
return "add(2,3) => 5"
elif method == 'pow':
return "pow(x, y[, z]) => number"
else:
# By convention, return empty
# string if no help is available
return ""
|
_marshaled_dispatch处理最关键的rpc实现:
1
2
3
4
5
6
7
8
9
10
11
|
def _marshaled_dispatch(self, data, dispatch_method = None, path = None):
try:
...
except:
# report exception back to server
exc_type, exc_value, exc_tb = sys.exc_info()
try:
...
finally:
# Break reference cycle
exc_type = exc_value = exc_tb = None
|
这一部分在之前的文章[xmlrpc源码阅读]中有过介绍,就不再重复介绍。这次我们重点关注一下异常处理部分。请看示例:
1
2
3
4
5
6
7
8
9
10
|
def some(x, y):
z = x / y
return z
try:
some(1, 0)
except:
exc_type, exc_value, exc_tb = sys.exc_info()
print(exc_type, exc_value)
print(repr(traceback.extract_tb(exc_tb)))
|
从下面的日志输出可以看到,使用traceback可以得到异常的调用堆栈信息,这对定位bug非常有帮助:
1
2
3
4
5
6
7
8
|
<class 'ZeroDivisionError'> division by zero
[<FrameSummary file /Users/*/work/yuanmahui/python/ch18-rpc/sample.py, line 59 in test_exec>, <FrameSummary file /Users/*/work/yuanmahui/python/ch18-rpc/sample.py, line 55 in some>]
Traceback (most recent call last):
File "/Users/yoo/work/yuanmahui/python/ch18-rpc/sample.py", line 59, in test_exec
some(1, 0)
File "/Users/yoo/work/yuanmahui/python/ch18-rpc/sample.py", line 55, in some
z = x / y
ZeroDivisionError: division by zero
|
_dispatch同样在之前的文章[xmlrpc源码阅读]中有过详细介绍,这次关注一下函数参数的自动封箱与拆箱:
1
2
3
|
def _dispatch(self, method, params):
...
return func(*params)
|
下面代码显示了如何使用args传递参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def some(a, b, c=2):
print(a, b, c)
def f(args):
some(*args)
def f2(*args):
some(*args)
# 0 1 2
f((0, 1))
f((1, 2, 3))
# a b c # 这样竟然也可以...
f({"a": 4, "b": 5, "c": 6})
f2(*(1, 2, 3))
f2(1, 2, 3)
|
- 总结
*args在函数定义中,会自动把位置参数进行封箱(多个参数合并成一个元祖参数,就像用箱子封装一样)成元祖; *args在函数调用的时候,又自动把元祖参数拆箱成多个参数。
SimpleXMLRPCRequestHandler分析
SimpleXMLRPCRequestHandler继承自BaseHTTPRequestHandler。 encode_threshold定义了一个MTU推荐值,就是一个tcp包的在网络传输过程中的上限大小。如果超过则会拆分成多个IP包进行传输,这样会有多次网络传输,效率会变低。解决的办法就是超过MTU值的数据使用gzip压缩算法:
1
2
3
4
5
6
7
8
9
10
11
12
|
#if not None, encode responses larger than this, if possible
encode_threshold = 1400 #a common MTU
...
if self.encode_threshold is not None:
if len(response) > self.encode_threshold:
q = self.accept_encodings().get("gzip", 0)
if q:
try:
response = gzip_encode(response)
self.send_header("Content-Encoding", "gzip")
|
SimpleXMLRPCRequestHandler有多个类属性:
1
2
3
4
5
|
class SimpleXMLRPCRequestHandler(BaseHTTPRequestHandler):
...
wbufsize = -1
disable_nagle_algorithm = True
...
|
类属性如果希望被扩展,可以使用小写;如果不推荐扩展,可以使用大写,类似常量定义:
1
2
3
4
5
6
7
8
|
# bottle
class BaseRequest(object):
#: Maximum size of memory buffer for :attr:`body` in bytes.
MEMFILE_MAX = 102400
#: Maximum number pr GET or POST parameters per request
MAX_PARAMS = 100
|
如果希望提供常量值,又可以被扩展,可以参考下面的写法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# http.server
DEFAULT_ERROR_CONTENT_TYPE = "text/html;charset=utf-8"
DEFAULT_ERROR_MESSAGE = """..."""
class BaseHTTPRequestHandler(socketserver.StreamRequestHandler):
sys_version = "Python/" + sys.version.split()[0]
server_version = "BaseHTTP/" + __version__
error_message_format = DEFAULT_ERROR_MESSAGE
error_content_type = DEFAULT_ERROR_CONTENT_TYPE
default_request_version = "HTTP/0.9"
|
http头上的Accept-Encoding可以使用下面的正则进行解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# a re to match a gzip Accept-Encoding
aepattern = re.compile(r"""
\s* ([^\s;]+) \s* #content-coding
(;\s* q \s*=\s* ([0-9\.]+))? #q
""", re.VERBOSE | re.IGNORECASE)
def accept_encodings(self):
r = {}
ae = self.headers.get("Accept-Encoding", "")
for e in ae.split(","):
match = self.aepattern.match(e)
if match:
v = match.group(3)
v = float(v) if v else 1.0
r[match.group(1)] = v
return r
|
下面是一些常见的Accept-Encoding举例:
1
2
3
4
5
6
|
Accept-Encoding: gzip
Accept-Encoding: gzip, compress, br
Accept-Encoding: br;q=1.0, gzip;q=0.8, *;q=0.1
# q 介于0和1之间,不存在则为1,数值表示优先级
|
do_POST函数一样,查看一下500状态的处理:
1
2
3
4
5
6
7
8
9
10
|
except Exception as e: # This should only happen if the module is buggy
self.send_response(500)
# Send information about the exception if requested
if hasattr(self.server, '_send_traceback_header') and \
self.server._send_traceback_header:
self.send_header("X-exception", str(e))
trace = traceback.format_exc()
trace = str(trace.encode('ASCII', 'backslashreplace'), 'ASCII')
self.send_header("X-traceback", trace)
|
- 这里定义了X-exception和X-traceback两个特别的http头,一般来说使用
X-前缀表示自定义的头,在django中会看到这种方式。
decode_request_content函数处理请求数据,下面是调用方法和函数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def do_POST(self):
data = self.decode_request_content(data)
if data is None:
return #response has been sent
...
self.send_response(200)
...
self.end_headers()
self.wfile.write(response)
def decode_request_content(self, data):
#support gzip encoding of request
encoding = self.headers.get("content-encoding", "identity").lower()
if encoding == "identity":
return data
if encoding == "gzip":
try:
return gzip_decode(data)
except NotImplementedError:
self.send_response(501, "encoding %r not supported" % encoding)
except ValueError:
self.send_response(400, "error decoding gzip content")
else:
self.send_response(501, "encoding %r not supported" % encoding)
self.send_header("Content-length", "0")
self.end_headers()
|
个人觉得,这个函数实现不太好。如果解析请求失败,异常处理header在另外的地方,导致逻辑结构不对等。我尝试修改一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
error_code, error_info = None, None
if encoding == "identity":
return 0, data
if encoding == "gzip":
try:
return 0, gzip_decode(data)
except NotImplementedError:
error_code, error_info = 501, "encoding %r not supported" % encoding
except ValueError:
error_code, error_info = 400, "error decoding gzip content"
else:
error_code, error_info = 501, "encoding %r not supported" % encoding
return error_code, error_info
|
这样关于header解析失败的逻辑在do_POST中实现,更统一。这里的error_code参考了golang的语法实现。大家觉得呢?欢迎在评论区留言点评。
log_request中使用了比较老式的调用父类方法的语法,而不是使用super关键字:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class BaseHTTPRequestHandler(socketserver.StreamRequestHandler):
def log_request(self, code='-', size='-'):
"""Log an accepted request.
This is called by send_response().
"""
if isinstance(code, HTTPStatus):
code = code.value
self.log_message('"%s" %s %s',
self.requestline, str(code), str(size))
class SimpleXMLRPCRequestHandler(BaseHTTPRequestHandler):
def log_request(self, code='-', size='-'):
"""Selectively log an accepted request."""
if self.server.logRequests:
BaseHTTPRequestHandler.log_request(self, code, size)
|
SimpleXMLRPCServer 分析
SimpleXMLRPCServer展示多类继承时候的父类初始化方法,不同的父类的初始化参数不一样:
1
2
3
4
5
6
7
8
|
class SimpleXMLRPCServer(socketserver.TCPServer,
SimpleXMLRPCDispatcher):
def __init__(self, addr, requestHandler=SimpleXMLRPCRequestHandler,
logRequests=True, allow_none=False, encoding=None,
bind_and_activate=True, use_builtin_types=False):
SimpleXMLRPCDispatcher.__init__(self, allow_none, encoding, use_builtin_types)
socketserver.TCPServer.__init__(self, addr, requestHandler, bind_and_activate)
|
MultiPathXMLRPCServer && CGIXMLRPCRequestHandler
MultiPathXMLRPCServer支持注册多个dispatcher实现,每个dispatcher支持不同的rpc路径,不像SimpleXMLRPCServer仅支持/RPC2,功能更强劲:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class MultiPathXMLRPCServer(SimpleXMLRPCServer):
def __init__(...):
self.dispatchers = {}
def add_dispatcher(self, path, dispatcher):
self.dispatchers[path] = dispatcher
return dispatcher
def _marshaled_dispatch(self, data, dispatch_method = None, path = None):
...
response = self.dispatchers[path]._marshaled_dispatch(
data, dispatch_method, path)
...
|
CGIXMLRPCRequestHandler提供了一种CGI实现。CGI在之前的[python http 源码阅读]有过介绍,特点就是输入输出使用标准流,CGI现在用的较少,简单了解即可。
1
2
3
4
5
6
7
8
9
10
|
CGIXMLRPCRequestHandler(SimpleXMLRPCDispatcher)
def handle_xmlrpc(self, request_text):
...
sys.stdout.buffer.write(response)
sys.stdout.buffer.flush()
...
def handle_request(self, request_text=None):
...
request_text = sys.stdin.read(length)
...
|
rpc-doc
ServerHTMLDoc, XMLRPCDocGenerator, DocXMLRPCRequestHandler和DocXMLRPCServer提供了更详细的RPC文档实现。文档对RPC服务来说非常重要,是RPC-client和RPC-server之间的重要规范,所以xmlrpc-server中用了大量篇幅来实现。不过,由于篇幅和时间原因,本文就不再进行详细分析其实现。
小结
xmlrpc-server核心由SimpleXMLRPCDispatcher,SimpleXMLRPCRequestHandler 和SimpleXMLRPCServer三个类实现,分工非常明确。 SimpleXMLRPCServer实现一个http服务,SimpleXMLRPCRequestHandler用于处理http请求和响应,SimpleXMLRPCDispatcher实现xml-rpc服务。当然其中还有一个核心的地方是dumps和loads方法,负责在http请求和rpc请求之间互换,这部分在client中,也先略过了。分拆类后,扩展性也很强,MultiPathXMLRPCServer扩展SimpleXMLRPCServer,实现多路径支持;CGIXMLRPCRequestHandler扩展SimpleXMLRPCDispatcher实现cgi支持;DocXMLRPCRequestHandler扩展SimpleXMLRPCRequestHandler实现文档支持。
MultiPathXMLRPCServer是前端控制器模式的实现,MultiPathXMLRPCServer充当了Front Controller的角色,支持多个dispatcher;SimpleXMLRPCDispatcher是Dispatcher的角色;而业务注册RPC函数,比如ExampleService.getData函数就是View了。这样就不是只会单例模式这一种设计模式,或者是设计模式一看就懂,一用就抓瞎。
小技巧
大家可以猜猜看,下图中的字符是什么?
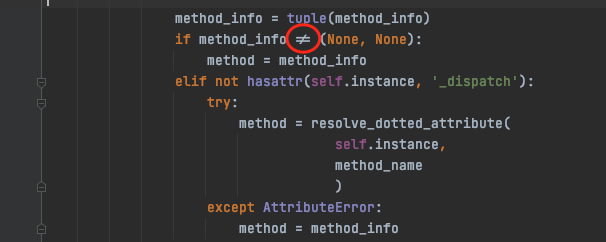
原创不易,欢迎加下面的微信和我互动交流,一起进阶:

参考链接