TinyDB是一个小型,简单易用,面向文档的数据库;代码仅1800行,纯python编写。TinyDB项目大小刚好,学习它可以了解NOSQL数据库的实现,本文包括下面几部分:
- TinyDB 项目结构简介
- TinyDB API设计
- storage 实现
- document && table 实现
- query 实现
- database 实现
- cache 实现
- 小结
- 小技巧
TinyDB 项目结构简介
本次阅读采用的版本号是 4.0.0, 项目结构如下:
| 文件 |
描述 |
| database |
database的实现 |
| middlewares |
中间件实现,包括cache |
| operations |
对database的一些操作方法 |
| queries |
查询功能实现 |
| storages |
存储功能实现 |
| table |
文档;表/集合功能实现 |
| utils |
工具类 |
| version |
版本号 |
项目的类图:
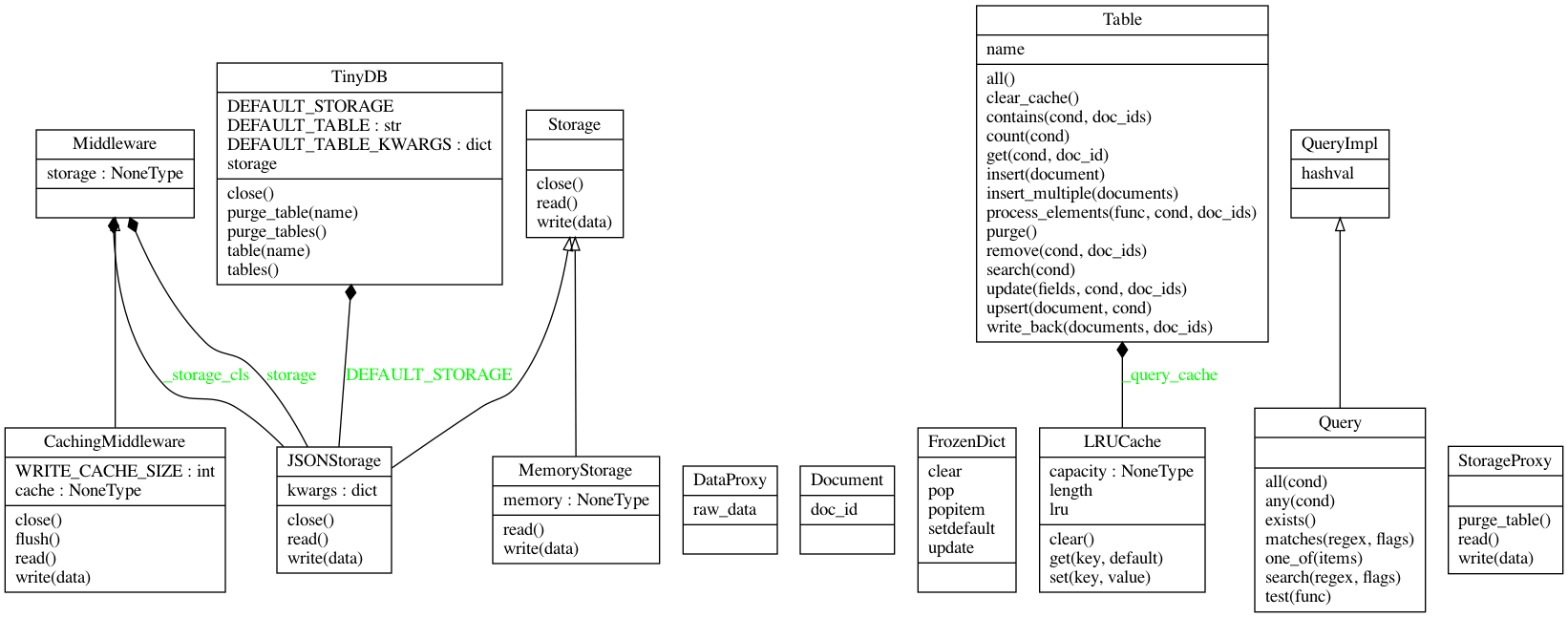
从类图可以看到,代码主要集中在database,table和query三个部分。
TinyDB API 设计
TinyDB的使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from tinydb import TinyDB
from tinydb import Query
from tinydb import JSONStorage
from tinydb.middlewares import CachingMiddleware
db = TinyDB('cache_db.json', storage=CachingMiddleware(JSONStorage))
db.purge_tables() # 重置数据
db.insert({'int': 1, 'char': 'a'}) # 插入数据
db.insert({'int': 2, 'char': 'b'})
table = db.table('user')
table.insert({'name': "shawn", "age": 18})
table.insert({'name': "shelton", "age": 28})
print(table.all()) # [{'name': 'shawn', 'age': 18}, {'name': 'shelton', 'age': 28}]
User = Query()
table.update({'name': 'shawn', 'age': 19}, User.name == 'shawn') # 修改数据
print(table.search(User.name == 'shawn')) # [{'name': 'shawn', 'age': 19}]
table.remove(User.name == 'shawn') # 删除数据
db.close()
|
上面的示例演示了数据库的CRUD等基础功能,可见tinydb的api非常简洁直观:
- TinyDB创建了database
- 使用db.table(‘user’)创建了新表user(默认是_default表)
- 使用talbe.insert插入数据
- 使用Query对象创建查询condition
- 使用table.search进行查询
- 使用table.update和table.remove进行更改和删除
从下面的数据文件cache_db.json,可以看到每个文档都有一个int型id,标识doc的唯一性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
"_default": {
"9": {
"int": 1,
"char": "a"
},
"10": {
"int": 2,
"char": "b"
}
},
"user": {
"2": {
"name": "shelton",
"age": 28
}
}
}
|
storage 实现
storages 包括下面3个类:
- storage 存储抽象类, 定义了read,write两个抽象方法和一个close空方法。
- MemoryStorage 基于内存的存储实现
- JSONStorage 基于JSON序列化的文件存储实现
先看简单的 MemoryStorage 实现:
1
2
3
4
5
6
7
8
9
10
11
|
class MemoryStorage(Storage):
def __init__(self):
super().__init__()
self.memory = None
def read(self) -> Optional[Dict[str, Dict[str, Any]]]:
return self.memory
def write(self, data: Dict[str, Dict[str, Any]]):
self.memory = data
|
storage的实现就是每次更换数据全量,这里的data是整个database的数据。
再看默认的 JSONStorage 实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
class JSONStorage(Storage):
"""
Store the data in a JSON file.
"""
def __init__(self, path: str, create_dirs=False, encoding=None, **kwargs):
super().__init__()
touch(path, create_dirs=create_dirs) # 创建文件及目录
self.kwargs = kwargs
self._handle = open(path, 'r+', encoding=encoding) # 文件读写
def close(self) -> None:
self._handle.close() # 文件存储,需要合法的关闭
def read(self) -> Optional[Dict[str, Dict[str, Any]]]:
self._handle.seek(0, os.SEEK_END)
size = self._handle.tell() # 判断文档内容大小
if not size:
return None
else:
self._handle.seek(0)
return json.load(self._handle) # 加载数据
def write(self, data: Dict[str, Dict[str, Any]]):
self._handle.seek(0)
serialized = json.dumps(data, **self.kwargs) # json序列化
self._handle.write(serialized)
self._handle.flush()
os.fsync(self._handle.fileno()) # 强制写入磁盘,保存数据
self._handle.truncate() # 截断原始数据
|
JSONStorage 主要就是文件的操作,然后进行json数据序列化和反序列化。官方的参考文档中还有扩展的 YAMLStorage ,大家可以通过参考链接自行去查看。
document && table 实现
document是普通字典+doc_id属性,非常简单
1
2
3
4
5
|
class Document(dict):
def __init__(self, value: Mapping, doc_id: int):
super().__init__(value)
self.doc_id = doc_id
|
Table的实现代码较多,先看构造方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
class Table:
document_class = Document # 存储数据类,可以被扩展
document_id_class = int # 数据主键,默认int,可以被扩展
query_cache_class = LRUCache # 查询缓存
default_query_cache_capacity = 10 # 查询缓存容量
def __init__(
self,
storage: Storage,
name: str,
cache_size: int = default_query_cache_capacity
):
self._storage = storage # 存储的引用
self._name = name # 表名
self._query_cache = self.query_cache_class(capacity=cache_size) \
# type: LRUCache[Query, List[Document]]
self._next_id = None # 主键记录
|
Table主要包括读和写两部分,我们先看写的代表 search 方法
1
2
3
4
5
6
7
8
9
10
11
12
|
def search(self, cond: Query) -> List[Document]:
if cond in self._query_cache: # 优先从查询缓存获取
docs = self._query_cache.get(cond)
if docs is not None:
return docs[:]
docs = [doc for doc in self if cond(doc)] # 使用Query判断数据是否符合条件
self._query_cache[cond] = docs[:] # 缓存下次使用
return docs
|
table 对象可以迭代,是因为实现了 iter 方法
1
2
3
4
5
6
7
8
9
10
11
|
def __iter__(self) -> Iterator[Document]:
"""
Iterate over all documents stored in the table.
:returns: an iterator over all documents.
"""
# Iterate all documents and their IDs
for doc_id, doc in self._read_table().items(): # 读取所有数据
# Convert documents to the document class
yield self.document_class(doc, doc_id) # 包装Document对象
|
重点之一在 read_table 方法实现:
1
2
3
4
5
6
7
8
9
|
def _read_table(self) -> Dict[int, Mapping]:
tables = self._storage.read() # 从storage读取数据
...
table = tables[self.name] # 获取当前表
...
return {
self.document_id_class(doc_id): doc
for doc_id, doc in table.items()
} # 生成全部数据
|
查询中还有一个重点在于查询条件的处理,这是由Query实现的,稍后再介绍。继续查看插入数据方法 insert 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def insert(self, document: Mapping) -> int:
...
doc_id = self._get_next_id() # 获取自增ID
def updater(table: dict):
...
table[doc_id] = dict(document) # 插入数据
self._update_table(updater) # 抽象的更新表方法
return doc_id
|
主键自增的 get_next_id 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def _get_next_id(self):
if self._next_id is not None: # 第一条记录
next_id = self._next_id
self._next_id = next_id + 1
return next_id # 快速返回
table = self._read_table() # 从存储中读取数据
if not table: # 空表
next_id = 1
self._next_id = next_id + 1
return next_id
# 查找已有数据的最大主键
max_id = max(self.document_id_class(i) for i in table.keys())
self._next_id = max_id + 1 # 主键自增
return self._next_id
|
更新数据最重要的 update_table :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
def _update_table(self, updater: Callable[[Dict[int, Mapping]], None]):
tables = self._storage.read() # 载入已有database数据
if tables is None:
# The database is empty
tables = {}
try:
raw_table = tables[self.name] # 读取table数据
except KeyError:
# The table does not exist yet, so it is empty
raw_table = {}
# 转换document对象
table = {
self.document_id_class(doc_id): doc
for doc_id, doc in raw_table.items()
}
updater(table) # 更新数据
tables[self.name] = {
str(doc_id): doc
for doc_id, doc in table.items()
} # 封装document
self._storage.write(tables) # 写入数据
self.clear_cache() # 数据变动,清空查询缓存
|
可以看到更新数据模版主要步骤是:
- 读取数据(database&&table)
- 封装document对象
- 更新数据
- 写入数据
- 清理缓存
query 实现
query是可以进行布尔运算和算术运算的conditon,由QueryInstance父类和Query子类两级实现。QueryInstance定义了布尔运算的规则,Query定义了算术运算的规则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class QueryInstance:
def __init__(self, test: Callable[[Mapping], bool], hashval: Tuple):
self._test = test # 计算函数
self._hash = hashval # hash值
def __call__(self, value: Mapping) -> bool: # 执行获取布尔值
return self._test(value)
def __hash__(self):
return hash(self._hash)
def __repr__(self):
return 'QueryImpl{}'.format(self._hash)
def __eq__(self, other: object):
if isinstance(other, QueryInstance): # 类型和hash相同
return self._hash == other._hash
return False
|
QueryInstance使用hash值确定对象的唯一性,布尔运算 and, or 和 not 也都是基于对象的hash判断。frozenset 是给对象计算hash值的关键函数,在utils中提供。
1
2
3
4
5
6
7
8
9
10
11
|
def __and__(self, other: 'QueryInstance') -> 'QueryInstance':
return QueryInstance(lambda value: self(value) and other(value),
('and', frozenset([self._hash, other._hash])))
def __or__(self, other: 'QueryInstance') -> 'QueryInstance':
return QueryInstance(lambda value: self(value) or other(value),
('or', frozenset([self._hash, other._hash])))
def __invert__(self) -> 'QueryInstance':
return QueryInstance(lambda value: not self(value),
('not', self._hash))
|
Query子类中定义了算术运算的函数,包括:
- eq 相等
- ne 不等
- lt 小于
- le 小于等于
- gt 大于
- ge 大于等于
算术运算和布尔运算不同,是基于Query对象的条件进行判断:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
def _generate_test(
self,
test: Callable[[Any], bool],
hashval: Tuple,
) -> QueryInstance:
def runner(value):
try:
# Resolve the path
for part in self._path:
value = value[part] # 字典取值
except (KeyError, TypeError):
return False
else:
return test(value)
return QueryInstance(
lambda value: runner(value),
hashval
)
def __eq__(self, rhs: Any):
"""
Test a dict value for equality.
>>> Query().f1 == 42
:param rhs: The value to compare against
"""
return self._generate_test(
lambda value: value == rhs, # 判断逻辑,使用匿名函数
('==', self._path, freeze(rhs))
)
|
query对象的条件是这样设置的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# Query().f1 == 42
def __getattr__(self, item: str):
# Generate a new query object with the new query path
# We use type(self) to get the class of the current query in case
# someone uses a subclass of ``Query``
query = type(self)() # 新生成query对象
# Now we add the accessed item to the query path ...
query._path = self._path + (item,)
# ... and update the query hash
query._hash = ('path', query._path)
return query
|
query还提供了一些api: exists, matches, search, test, any, all 和 one_of 进行集合判断。
database 实现
database只是维护表的集合和存储,整体实现很简单:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class TinyDB:
table_class = Table
default_table_name = '_default'
default_storage_class = JSONStorage # 默认存储实现,可以扩展
def __init__(self, *args, **kwargs):
storage = kwargs.pop('storage', self.default_storage_class)
self._storage = storage(*args, **kwargs) # 准备存储实现
self._opened = True
self._tables = {} # 支持多表
def __getattr__(self, name):
return getattr(self.table(self.default_table_name), name)
# db.insert({'int': 1, 'char': 'a'}) # insert语法通过getattr透传到default-table
|
cache 实现
cache是数据库的重要实现,tinydb提供了2种cache。一种是table的query-cache, 比如之前的search查询:
1
2
3
4
5
6
|
def search(self, cond: Query) -> List[Document]:
if cond in self._query_cache:
docs = self._query_cache.get(cond)
if docs is not None:
return docs[:]
...
|
查询缓存使用LRU实现,LRU全称Least Recently Used:最近最少使用淘汰算法。同类的还有,LFU全称Least Frequently Used),最不经常使用淘汰算法。LFU是淘汰一段时间内,使用次数最少的数据;LRU是淘汰最长时间没有被使用的数据,更多说明请见参考链接。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
class LRUCache(abc.MutableMapping, Generic[K, V]):
def __init__(self, capacity=None):
self.capacity = capacity # 缓存容量
self.cache = OrderedDict() # 有序字典
def get(self, key: K, default: D = None) -> Optional[Union[V, D]]:
value = self.cache.get(key) # 从换成获取
if value is not None:
del self.cache[key]
self.cache[key] = value # 更新缓存顺序
return value
return default
def set(self, key: K, value: V):
if self.cache.get(key):
del self.cache[key]
self.cache[key] = value # 更新缓存顺序及值
else:
self.cache[key] = value
if self.capacity is not None and self.length > self.capacity:
self.cache.popitem(last=False) # 淘汰最古老的数据
|
虽然LRUCache的实现比较简单,容量无法字典增长,数据每次淘汰一条比较低效,但是也体现了缓存实现的主要特点:
- 设置容量上限,防止无限增长
- 有序存储数据,每次获取或者修改都要更新一下数据的排序
- 达到容量上限后进行数据淘汰
另外一种cache是,数据写入的cache。默认的storage中,每次有数据更新都要写入磁盘,这样效率较低,cachemiddleware中对数据进行缓存,变成N次数据变动后一次写入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
class CachingMiddleware(Middleware):
WRITE_CACHE_SIZE = 1000 # 变动上限
def __init__(self, storage_cls):
super().__init__(storage_cls)
self.cache = None
self._cache_modified_count = 0 # 变动计数
def read(self):
if self.cache is None:
self.cache = self.storage.read() # 初始化
return self.cache
def write(self, data):
self.cache = data # 缓存数据
self._cache_modified_count += 1 # 计数增长
# 判读是否需要写入磁盘
if self._cache_modified_count >= self.WRITE_CACHE_SIZE:
self.flush()
def close(self): # 安全关闭
self.flush()
self.storage.close()
|
小结
我们可以简单小结一下文档型数据库的实现:
- storage 数据存储实现
- database && table 数据库和表的实现
- query 查询规则的实现
- cache 优化和提高数据库的查询和存储效率
小技巧
python 抽象类在 ABC 模块中提供,使用 abstractmethod 配合 NotImplementedError 异常定义:
1
2
3
4
5
6
7
8
9
10
11
12
|
class Storage(ABC):
@abstractmethod
def read(self) -> Optional[Dict[str, Dict[str, Any]]]:
raise NotImplementedError('To be overridden!')
@abstractmethod
def write(self, data: Dict[str, Dict[str, Any]]) -> None:
raise NotImplementedError('To be overridden!')
def close(self) -> None:
pass
|
python3 支持数据类型的 annotation ,比如read方法约定了返回值是一个字典嵌套字典的参数或者None,所以是 Optional类型;write方法的数据也是字典嵌套,没有返回值。
1
2
3
4
5
6
7
8
9
|
from typing import Dict, Any, Optional
@abstractmethod
def read(self) -> Optional[Dict[str, Dict[str, Any]]]:
pass
@abstractmethod
def write(self, data: Dict[str, Dict[str, Any]]) -> None:
pass
|
类型注释还支持自引用:
1
2
3
|
def __and__(self, other: 'QueryInstance') -> 'QueryInstance': # 自引用的类型注释,当前QueryInstance类还未创建
return QueryInstance(lambda value: self(value) and other(value),
('and', frozenset([self._hash, other._hash])))
|
自定义对象的hash
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
class FrozenDict(dict):
def __hash__(self):
# 转换为元祖,利用元祖不可变的特性计算hash值
return hash(tuple(sorted(self.items())))
def _immutable(self, *args, **kws):
raise TypeError('object is immutable')
# Disable write access to the dict
__setitem__ = _immutable
__delitem__ = _immutable
clear = _immutable
setdefault = _immutable
popitem = _immutable
def update(self, e=None, **f):
raise TypeError('object is immutable')
def pop(self, k, d=None):
raise TypeError('object is immutable')
def freeze(obj):
"""
使用递归方式一个对象转换成可以hash的对象
"""
if isinstance(obj, dict):
# Transform dicts into ``FrozenDict``s
return FrozenDict((k, freeze(v)) for k, v in obj.items())
elif isinstance(obj, list):
# Transform lists into tuples
return tuple(freeze(el) for el in obj)
elif isinstance(obj, set):
# Transform sets into ``frozenset``s
return frozenset(obj)
else:
# Don't handle all other objects
return obj
|
tinydb项目使用 poetry 进行虚拟环境管理,关于poetry的使用请看Python虚拟环境指南2020版 ;使用 pytest 进行测试用例管理。
参考链接