为什么使用Pandas
文章目录
Pandas是一个开源的,BSD许可的库,为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。和Numpy,Matplotlib合称Python数据分析三剑客。
开始学习数据分析的时候,一直对为什么使用Pandas有疑问。Numpy已经足够强大,Matplotlib专注于数据可视化,那么Pandas是用来干什么的呢?官方是这样说:
- Python在数据处理和准备方面一直做得很好,但在数据分析和建模方面就没那么好了。Pandas帮助填补了这一空白,使您能够在Python中执行整个数据分析工作流程
- 与出色的 IPython 工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力方面都是卓越的
总结的很好,我想这对初学者心中的疑问并没有缓解多少。下面我尝试使用我的理解来回答这个问题,这不需要太多基础,大家可以放心食用。
Pandas支持文本索引
小恩同学某学期的成绩如下表:
| 数学 | 语文 | 英语 |
|---|---|---|
| 98 | 86 | 90 |
成绩在python中可以使用数组表示一维数据:
|
|
如果我们想知道小恩同学的语文成绩:
|
|
序号0,1,2分别表示数学,语文和英语的成绩。序号从0开始是python的规范。
如果我们想知道小恩同学的三科最高分和平均分呢?这需要一些数据处理,使用python实现很简单:
|
|
但是使用numpy更容易:
|
|
不知道大家有没有感受到这样定义一维数据有一个小小的但是又很有负担的问题。数据的标签丢失了,只能够使用序号0,1,2去取值。取完值后,还需要自己去查看数值序号对应的列标签。
pandas的Series是用来表示一维数据结构,很好的解决了这个问题:
|
|
我们可以看到pandas中可以使用s.chn或者s["chn"]这样的文本索引取值,更清晰明了。
同时pandas中也集成了一些常用统计方法,直接查看数据概况:
|
|
我们将小西同学的期末成绩也汇入到成绩表中:
| 姓名 | 数学 | 语文 | 英语 |
|---|---|---|---|
| 小恩 | 98 | 86 | 90 |
| 小西 | 96 | 92 | 93 |
这样成绩表就变成了二维数据了,在pandas中就需要使用另外一种数据结构DataFrame来定义:
|
|
我们使用数据,列名和行名(索引)定义了一个DataFrame对象,它和上面的成绩表一致。需要额外注意一下的是,为了让表格展示一致,这里将列标签定义为[“math”,“chn”,“eng”],索引标签定义为姓名[“xiaoen”,“xiaoxi”]。
当然行和列只是展示数据的一种视觉角度,在pandas中可以无缝快速转换:
|
|
在二维数据中,查找数据我们一般先找到对应的行,或者对应的列:
|
|
找到行/列后会得到一个Series数据对象,这样再查找对应行中的列/列中的行和前面Series语法一致。同样是查找小恩同学的语文成绩:
|
|
当然最简单的使用数字索引方式查找也是可以的:
|
|
- loc和iloc是不是不容易分清,把它理解成index of location就好了
我们可以看的无论数据是一维还是二维,Pandas都支持文本索引,这样使用起来会更方便。
Pandas数据格式化更直观
pandas中数据格式化做了优化,看起来更直观清晰。
在numpy中上面的成绩表,它看起来是这样的:
|
|
但是在pandas中,它看起来是这样的:
|
|
数据展示的时候经过格式化,对齐的更整齐。因为pandas和IPython的结合,在Jupyter中表现的更好:
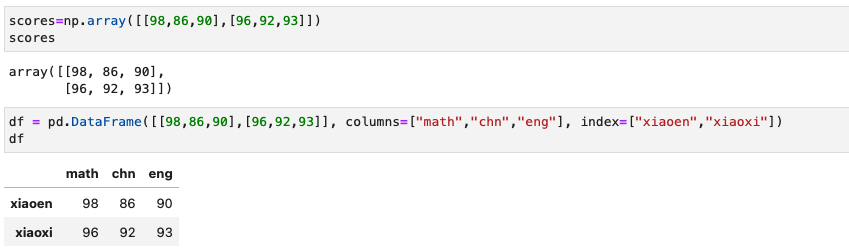
接下来所有数据展示都使用Jupyter中的形态
数据量大的时候,这个特点会更加突出。我们定义一个180行+3列的DataFrame数据:
|
|
它看起来是这样:
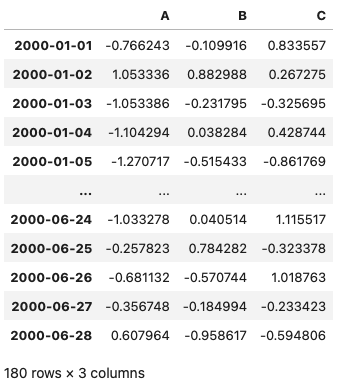 会自动省略中间段的数据,只显示头部和尾部的数据详情。
会自动省略中间段的数据,只显示头部和尾部的数据详情。
大家可以自己试试numpy中的数据显示,代码如下:
|
|
Pandas支持多级索引
我们继续往成绩表上汇入同学以及性别数据,如下:
| 姓名 | 性别 | 数学 | 语文 | 英语 |
|---|---|---|---|---|
| 小恩 | 男 | 98 | 86 | 90 |
| 小西 | 女 | 96 | 92 | 93 |
| 小游 | 男 | 84 | 78 | 70 |
| 小存 | 女 | 80 | 99 | 93 |
在pandas中可以使用多重索引定义:
|
|
数据长这样的:
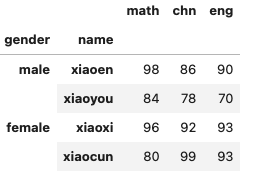
为了让二级索引看起来更清晰,我调整了一下数据的顺序。有了二级索引,我们可以很方便的查找女生/男生的成绩数据
|
|
Pandas支持动态结构数据
在之前的成绩表上,我们继续汇入一些选修课的成绩,扩充数据的维度:
| 姓名 | 性别 | 数学 | 语文 | 英语 | 政治 | 历史 | 物理 | 化学 |
|---|---|---|---|---|---|---|---|---|
| 小恩 | 男 | 98 | 86 | 90 | 89 | 78 | - | - |
| 小西 | 女 | 96 | 92 | 93 | 92 | 88 | - | - |
| 小游 | 男 | 84 | 78 | 70 | - | - | 89 | 78 |
| 小存 | 女 | 80 | 99 | 93 | - | - | 92 | 88 |
我们可以发现一些同学的选修课成绩是空,这样会浪费一些数据存储空间。如果在数据库中,我们大概会设计成这样:
| 姓名 | 性别 | 科目 | 成绩 |
|---|---|---|---|
| 小恩 | 男 | 数学 | 98 |
| 小恩 | 男 | 语文 | 86 |
| 小恩 | 男 | 英语 | 90 |
| 小恩 | 男 | 政治 | 89 |
| 小恩 | 男 | 历史 | 78 |
| 小西 | 女 | 数学 | 96 |
| 小西 | 女 | 语文 | 92 |
| 小西 | 女 | 英语 | 93 |
| 小西 | 女 | 政治 | 92 |
| 小西 | 女 | 历史 | 88 |
| 小游 | 男 | 数学 | 84 |
| 小游 | 男 | 语文 | 78 |
| 小游 | 男 | 英语 | 70 |
| 小游 | 男 | 物理 | 89 |
| 小游 | 男 | 化学 | 78 |
| 小存 | 女 | 数学 | 80 |
| 小存 | 女 | 语文 | 99 |
| 小存 | 女 | 英语 | 93 |
| 小存 | 女 | 物理 | 92 |
| 小存 | 女 | 化学 | 88 |
实际情况下会设计多张表比如成员信息表,科目数据表等
简单的说我们的数据结构中行是不确定的,列也是不确定。在pandas中这样定义:
|
|
- 注意我这里忽略了性别数据
它长这样:
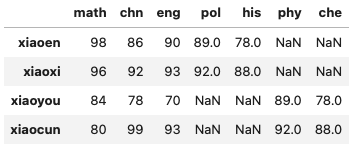
换个方式后查看:
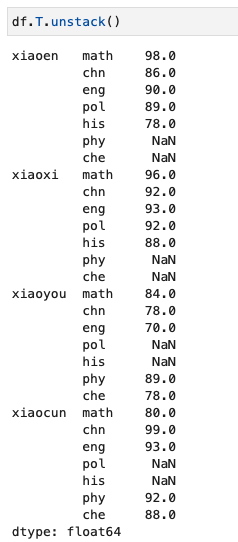
可能我们的上面数据最多只有7列,所以这种动态结构的支持会有点多此一举的味道。如果数据量变大后,这个特性就非常重要了。
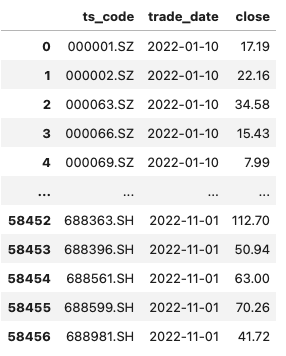
比如下面表是大A股2022年的所有票的收盘价,因为股票数量和日期的不确定,我们的结构化数据只能够使用下面方式构建:
在pandas中,我们可以很容易转换出m*n的多维表:
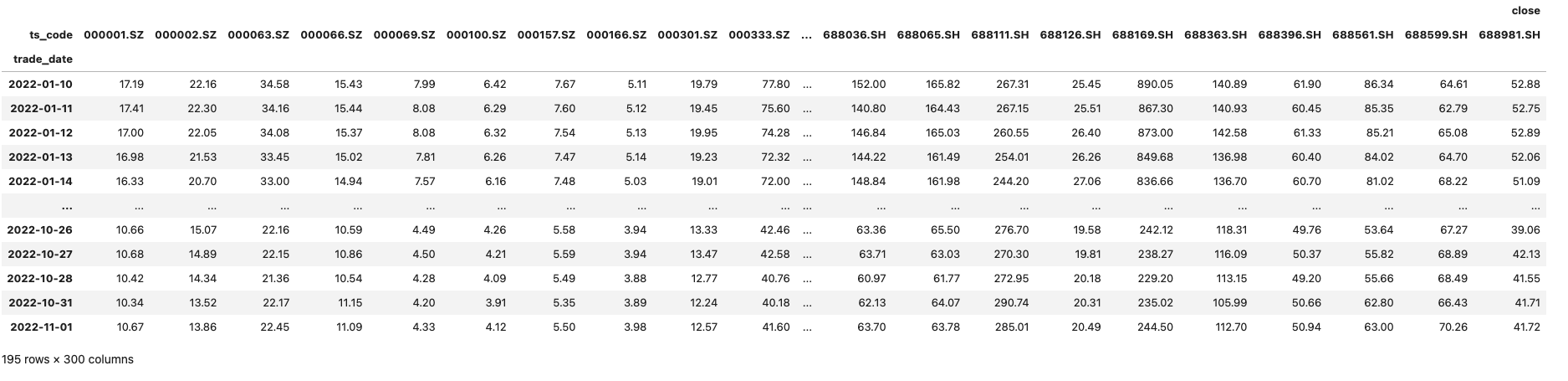
- 表的行和列都是不确定并且巨大的
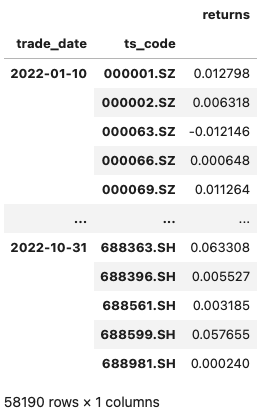
这种转换最主要的作用是可以快速的计算每只股票的收益率:
小结
我们从学生成绩开始,逐步从一维数据扩展到多维数据,从行列确定的静态数据结构到行列不确定的动态数据结构,演示了Pandas如何创建数据,并且如何和Jupyter结合更好的展示数据,这让数据分析更容易使用。
当然Pandas提供了更多更强大的功能,有兴趣的同学可以查看参考链接去了解。
参考链接
文章作者 shawn
上次更新 2023-02-12