像Excel一样使用Pandas
文章目录
像Excel一样使用Pandas
Pandas功能非常强大,API非常多。这次我们按照Excel的功能来探索Pandas的使用。同时为了更好的理解应用场景,我们从真实的数据出发,来探索数据中的真相。
本次选用的数据是kaggle提供的泰坦尼克号数据,刚好最近国内电影重映,大家一起深入了解一下这场世纪悲剧。
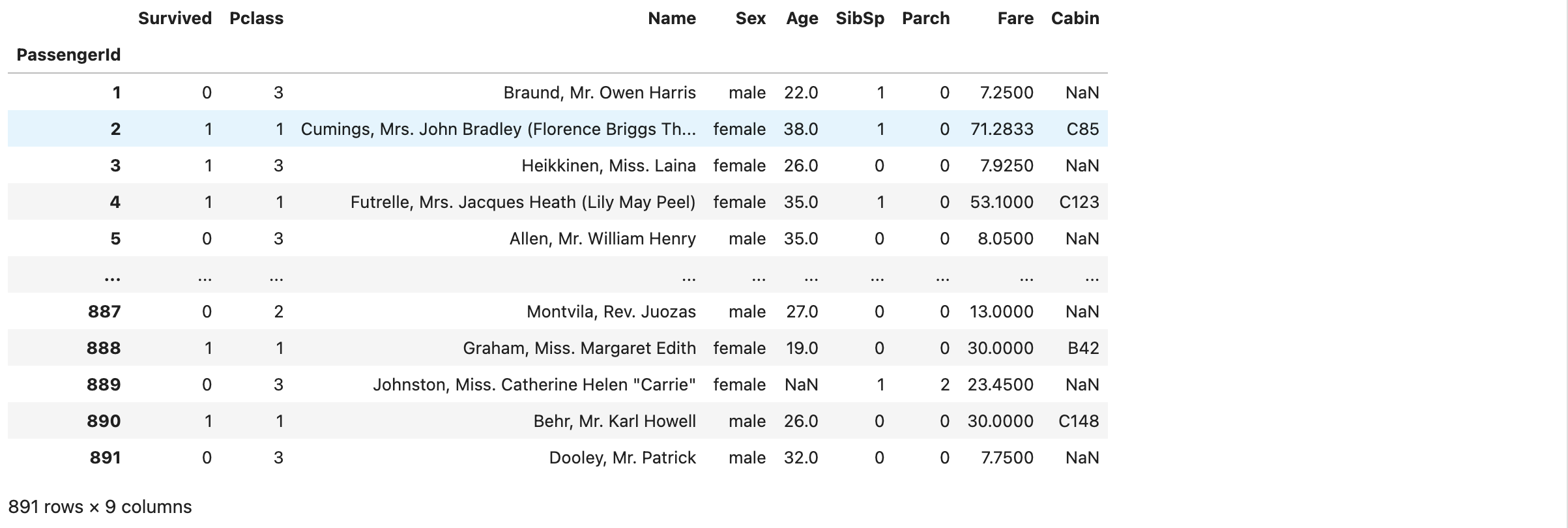
直接使用腾讯文档表格导入数据如下:
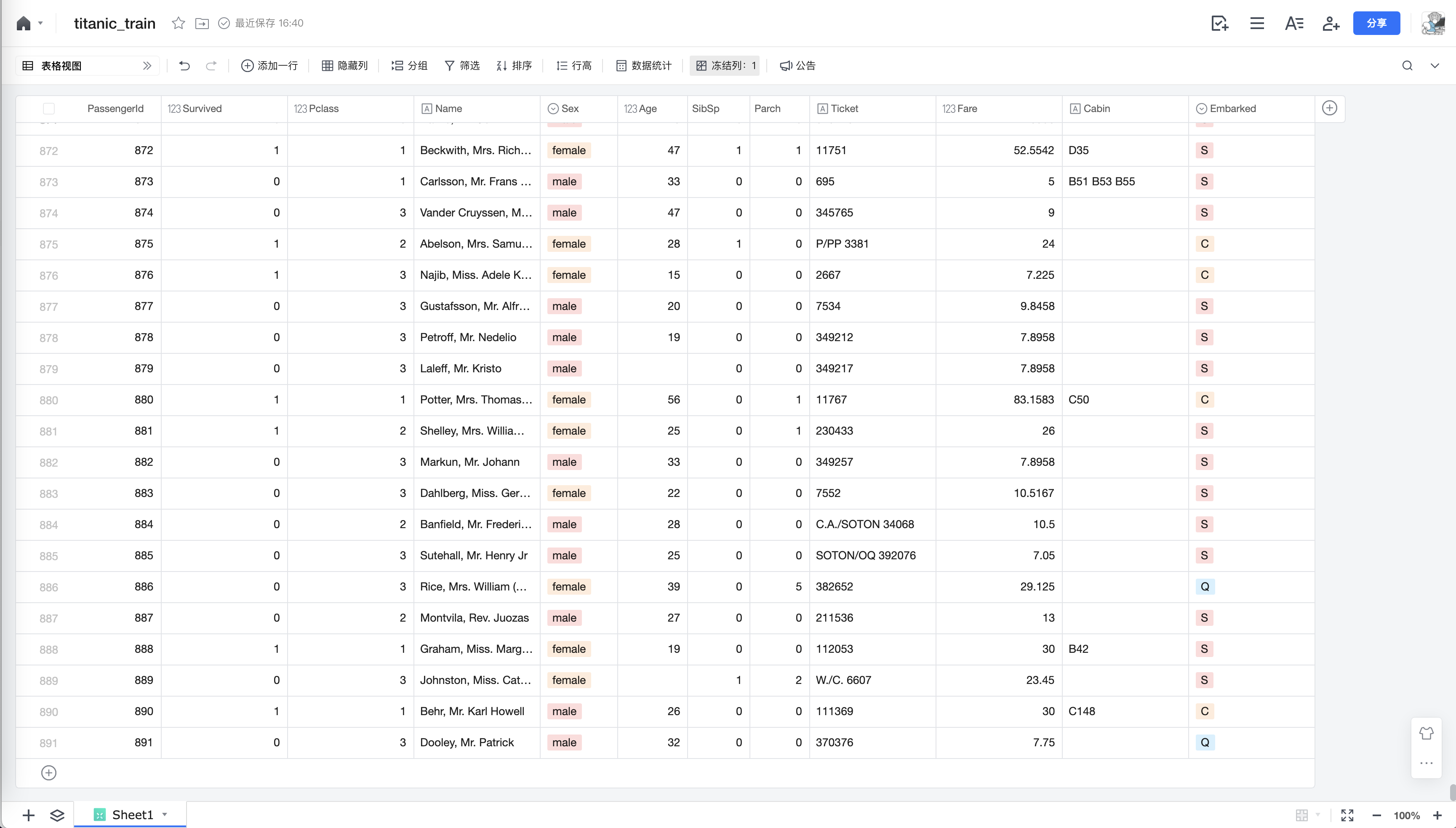
数据下载和在线链接都在文末的参考链接中
整个数据集大小是: 891行*12列数据。我们还需要了解一下各项数据的含义, 以更好的理解数据。
| 列 | 释义 |
|---|---|
| Survived | 是否存活,存活使用1表示 |
| Pclass | 船票等级, 船票等级数分1,2,3等座,越小级越高级 |
| Name | 乘客姓名 |
| Sex | 乘客性别 |
| Age | 乘客年龄 |
| SibSp | 乘客兄弟姐妹/配偶的个数 |
| Parch | 乘客父母/孩子的个数 |
| Ticket | 票编号 |
| Fare | 乘客所持票的价格 |
| Cabin | 乘客所在船舱 |
| Embark | 乘客登船港口 |
使用pandas可以这样导入数据:
|
|
在pandas中数据大概这样:
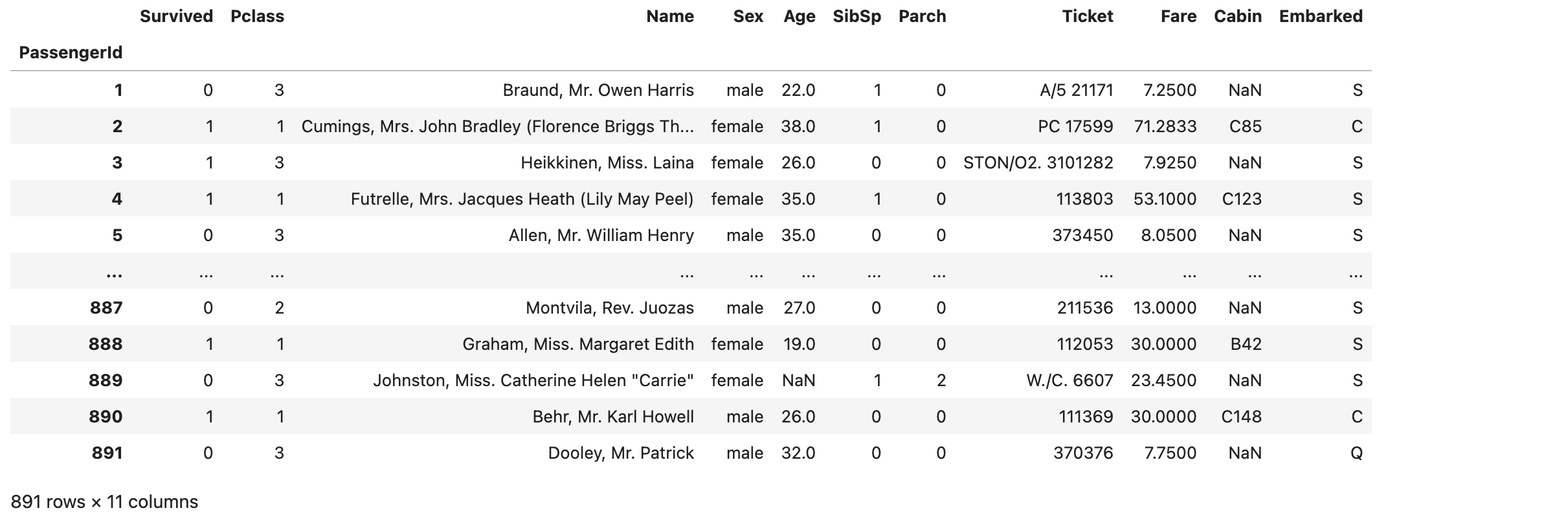
需要说明两点:
- PassengerId作为索引没有计算到columns(列)中,所以是891行*11列, 比excel少一列
- 空值自动转换成NaN,而不是excel中的空
接下来我们从execl的下面5个功能开始熟悉pandas
- 数据统计
- 隐藏列
- 排序
- 筛选
- 分组
数据统计
在excel中可以使用数据统计功能对数据进行简单分析:

从上图可以知道下面一些汇总信息:
- 总数计数,比如姓名891个
- 求和,比如总费用 28693.9493
- 未填写计数, 比如687个数据未记录船仓Cabin
- 分类,比如等级分三类,登船港口分三个
- 平均值,比如年龄均值29.69岁
在pandas中可以使用 info 查看信息:
|
|
显示数据:
- 年龄Age和船仓Cabin有缺失数据
- Name,Sex,Ticket,Cabin和Embarked是文本数据,其它为数字
也可以使用 describe 查看概况:
|
|
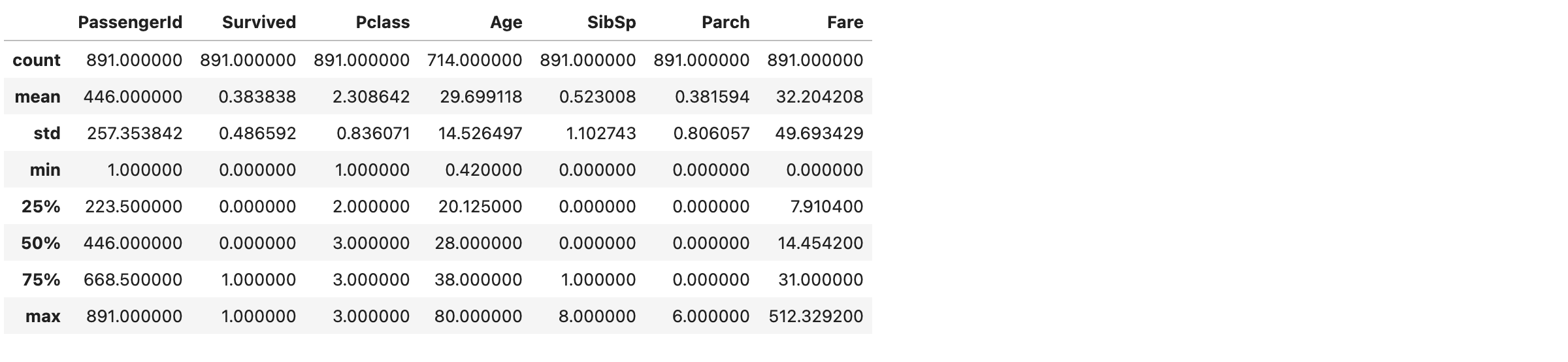
相比excel的数据统计,我们还可以得到一些更有用的结论/猜测:
- 年龄均值29.69, 最小4个月,最大80岁
- 存活均值0.38,不到四成的存活率( 一个悲伤的故事:( )
- 最便宜的船票大概是7.9(min=0估计是工作人员,排除在外), 最贵的门票512.32 (看来jack和rose贫富差距很大)
- 船票均价32约等于四分位数Q3的值31,7成人低于平均,金字塔结构下层穷人比较多(50的标准差也说明这个问题)
隐藏列
excel中可以隐藏一些列,让数据分析时候更聚焦。因为Ticket和Embarked和存活没有关系,我们隐藏这两列:
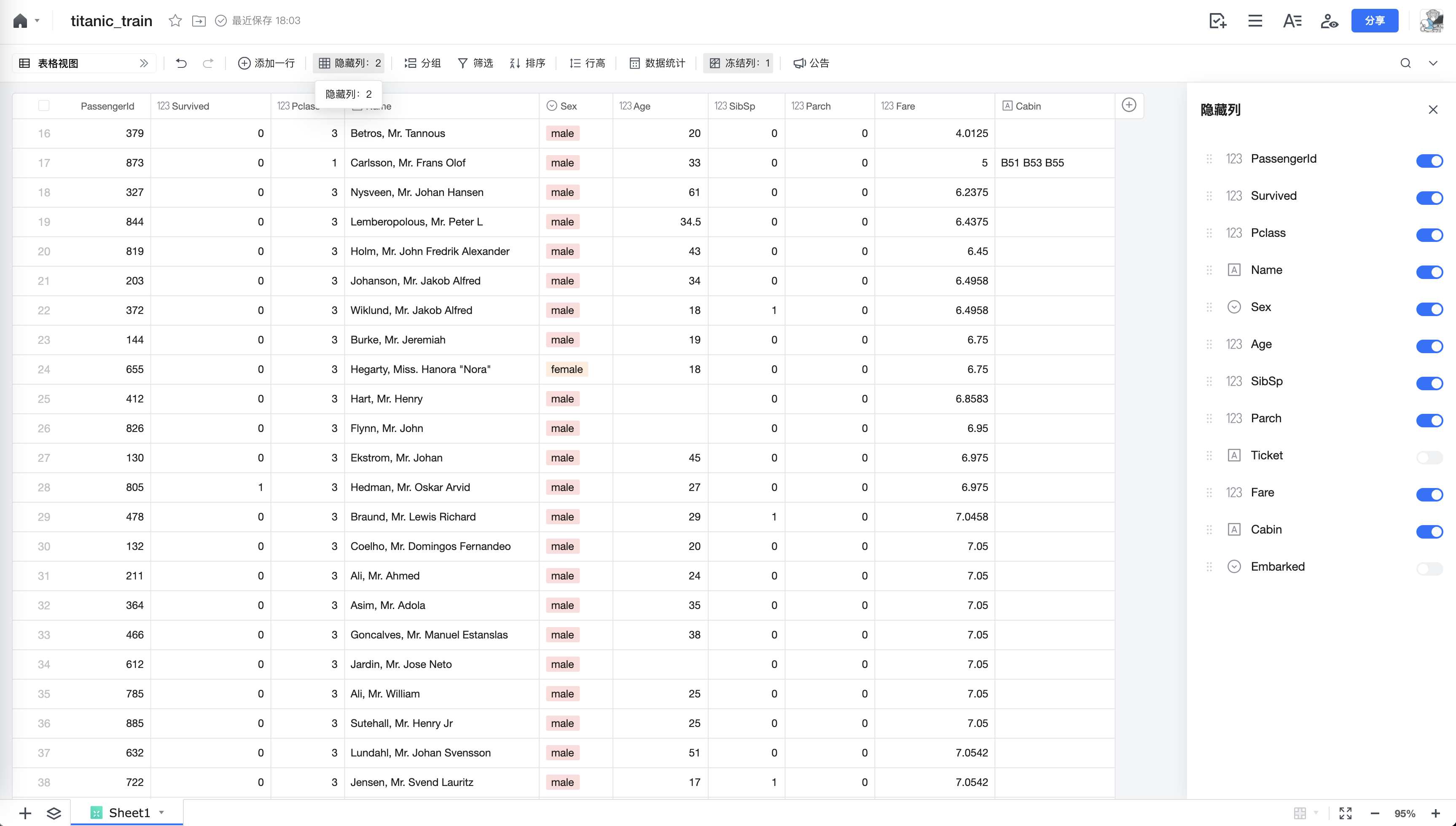
在pandas中直接drop这两列就好了:
|
|
- 11列变成9列
排序
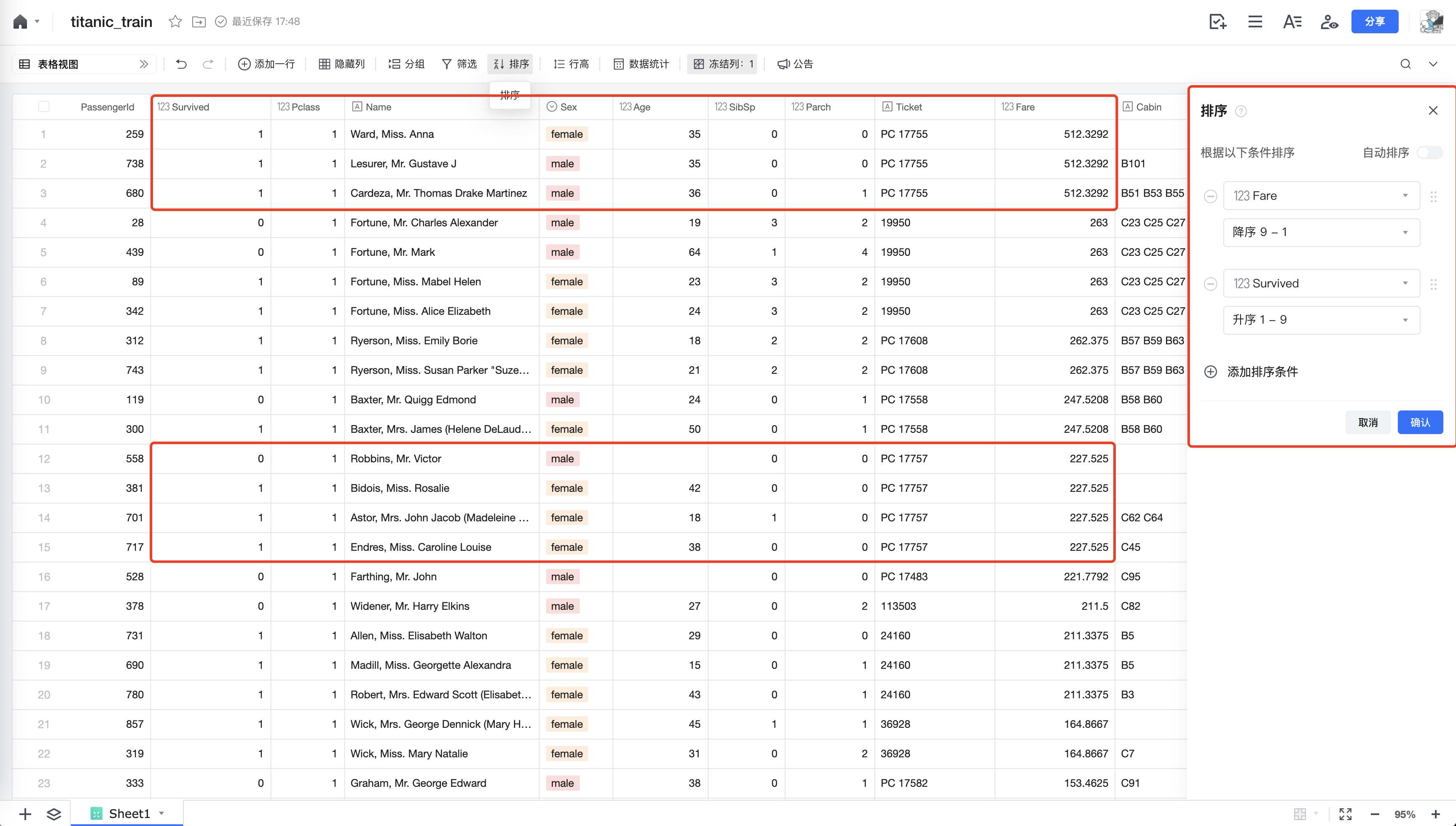
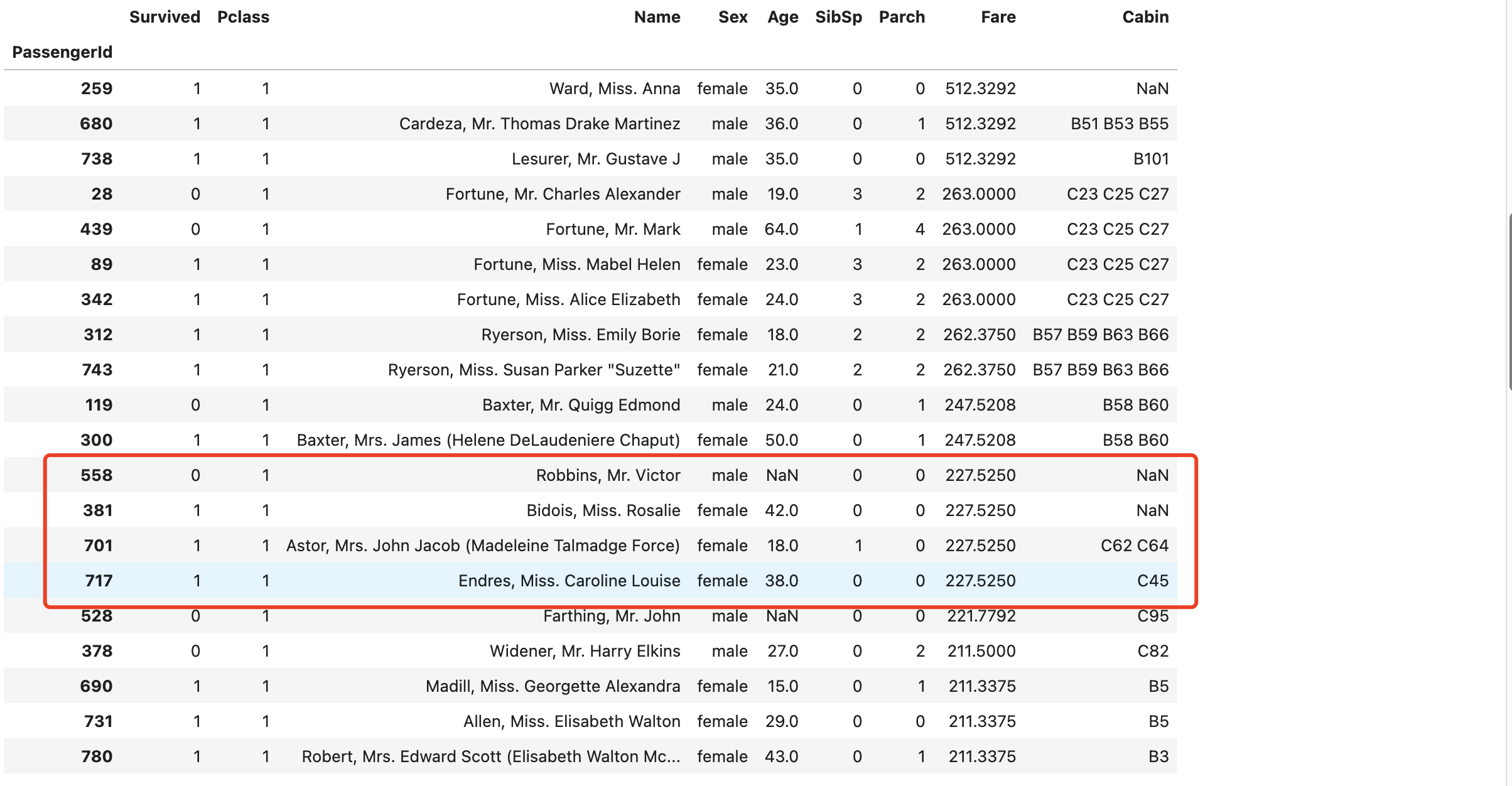
使用 船票降序,存活升序 多条件组合排序,可以猜测船票贵的可能存活率较高,其中最尊贵的的两位都存活了;女性存活率可能较高,比如227同等价位的,3位女性全部存活了。
更改一下船票使用升序,可以验证上面的猜测,满屏就805号幸运儿存活。
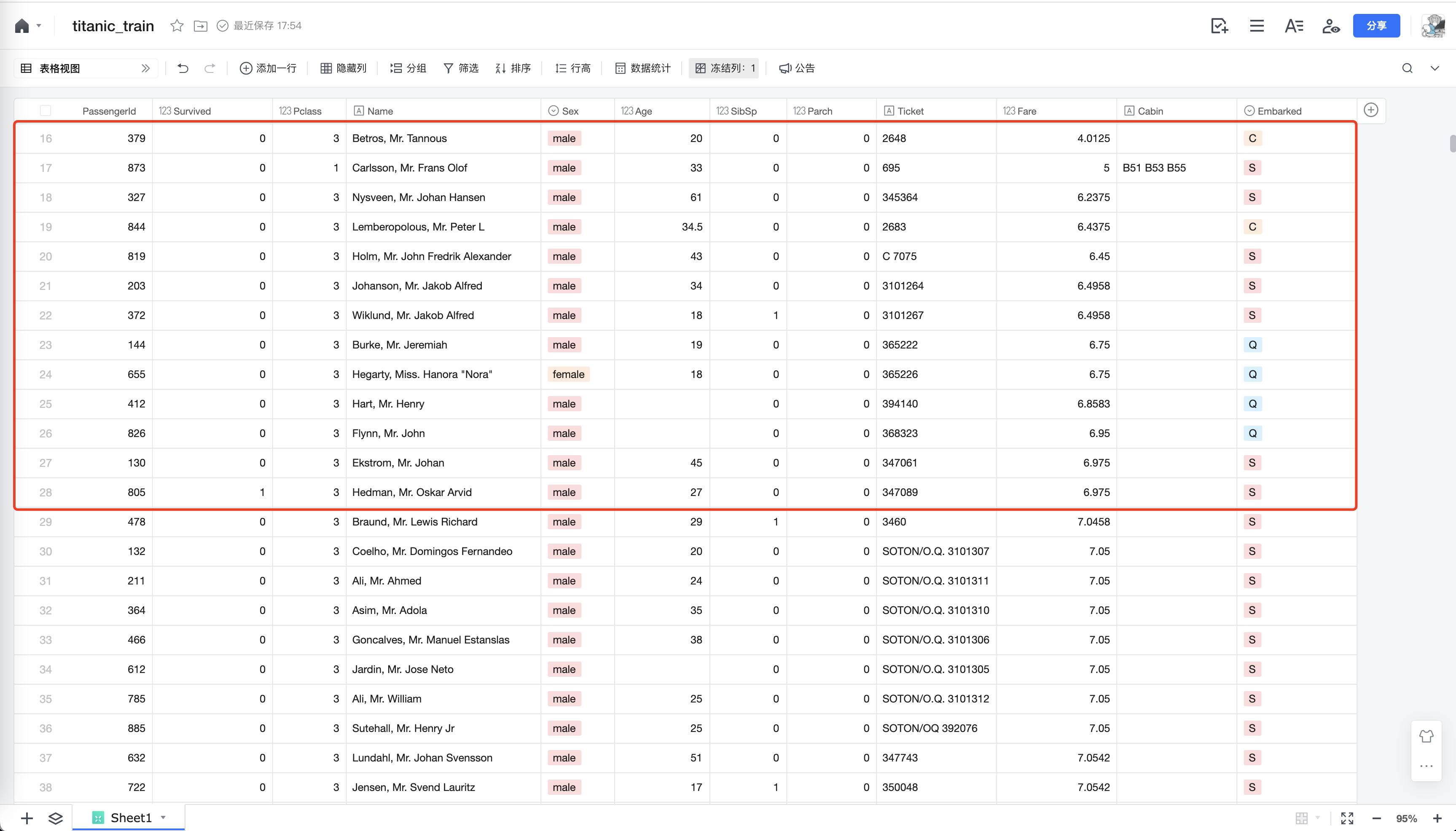
同时也可以发现一个有意思的特例数据,873号乘客是5元船票的1等座,价格和等级也不完全挂钩, 这个很重要。
在pandas中可以这样实现排序:
|
|
筛选
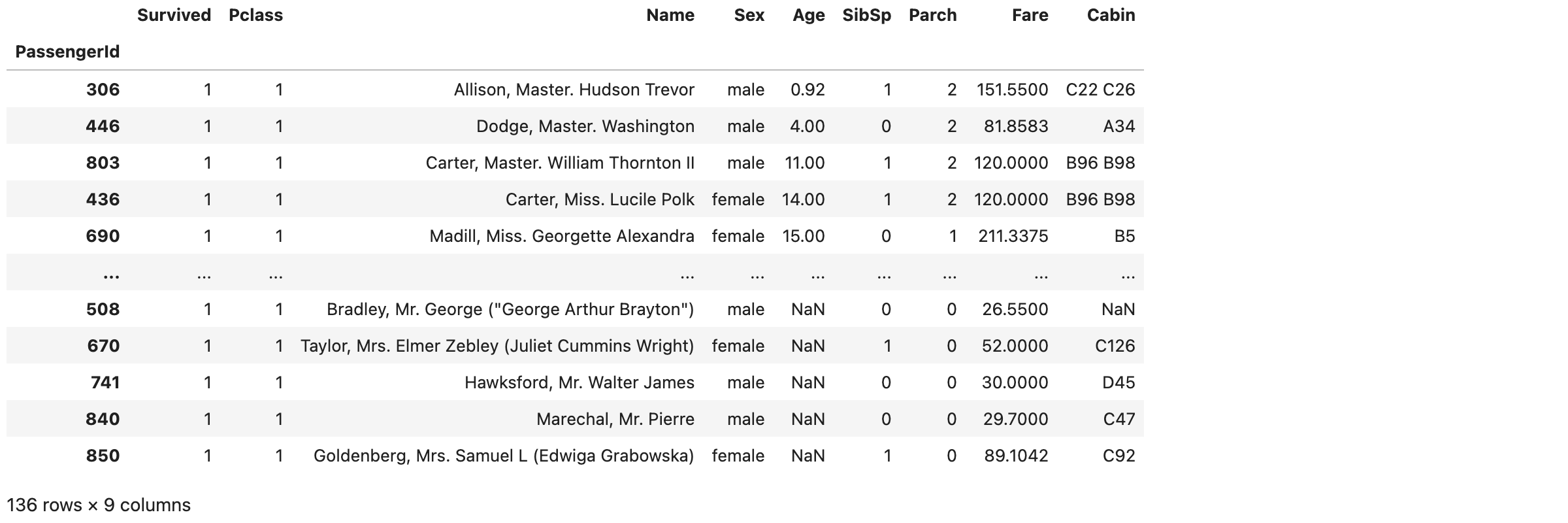
使用存活和船票等级筛选,并使用年龄降序,查找出可能最年幼的富豪:
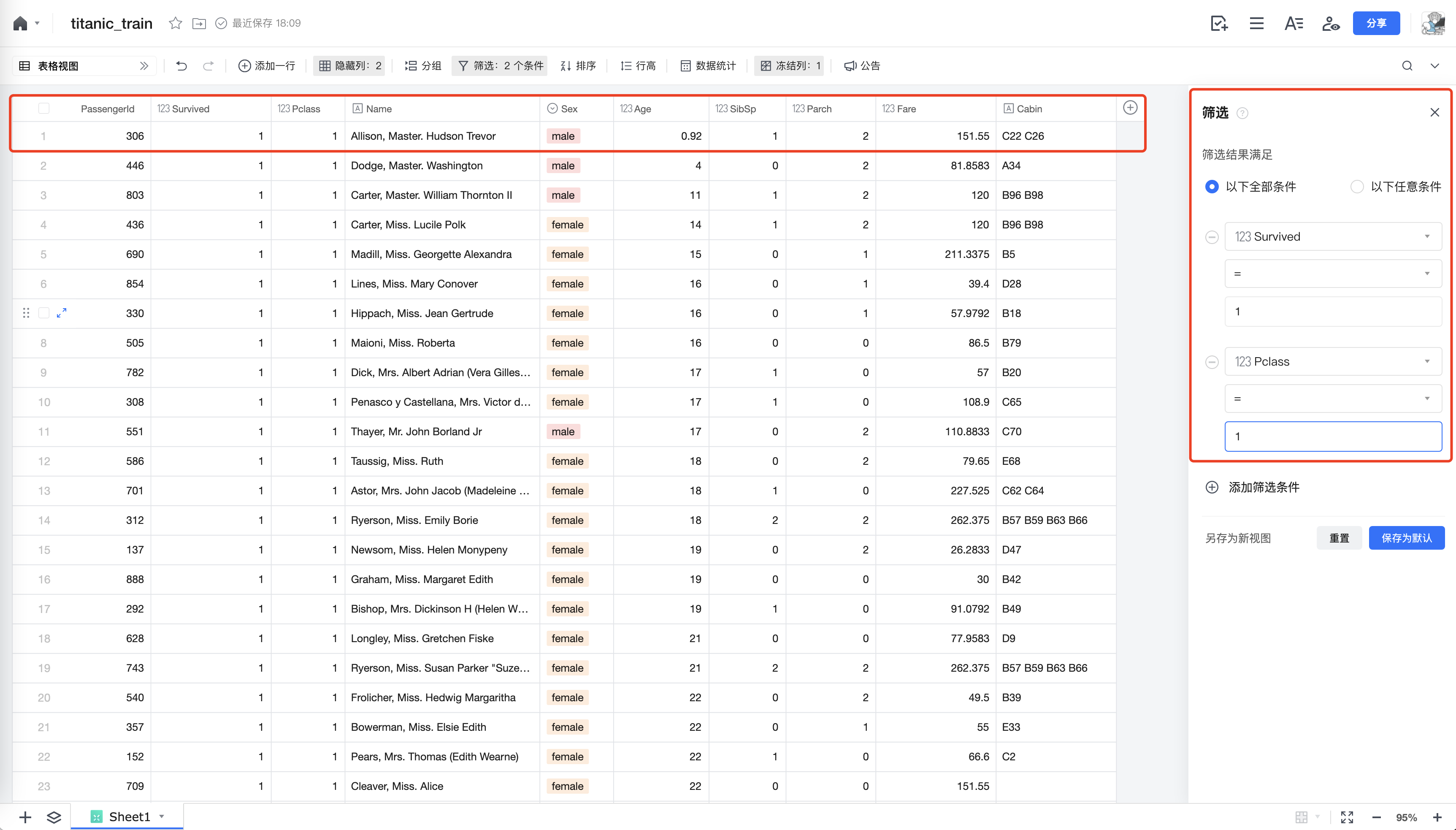
考虑到泰坦尼克号事故是1912年的,这位11个月大的幸存者可能也已经离世。查找新闻找到最后幸存者伊莉莎白·格拉迪斯·迪安(Elizabeth Gladys Dean)的报道(有兴趣的朋友可以看参考链接), 对应测试数据集中的1426号乘客,当时仅九周(不在本训练数据集中)。
在pandas中可以这样实现这个筛选及排序:
|
|
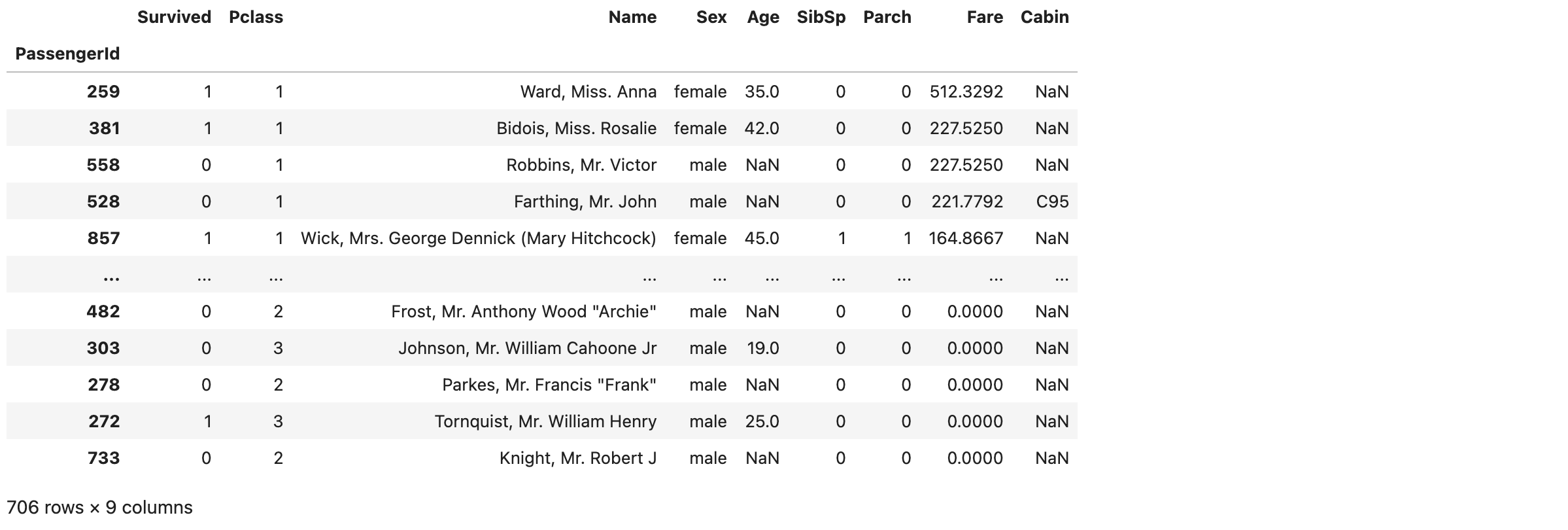
和excel筛选一样,也可以选择任意条件,比如找出有空数据的行:
|
|
分组
excel中可以使用分组功能,对数据进行一些展示和统计:
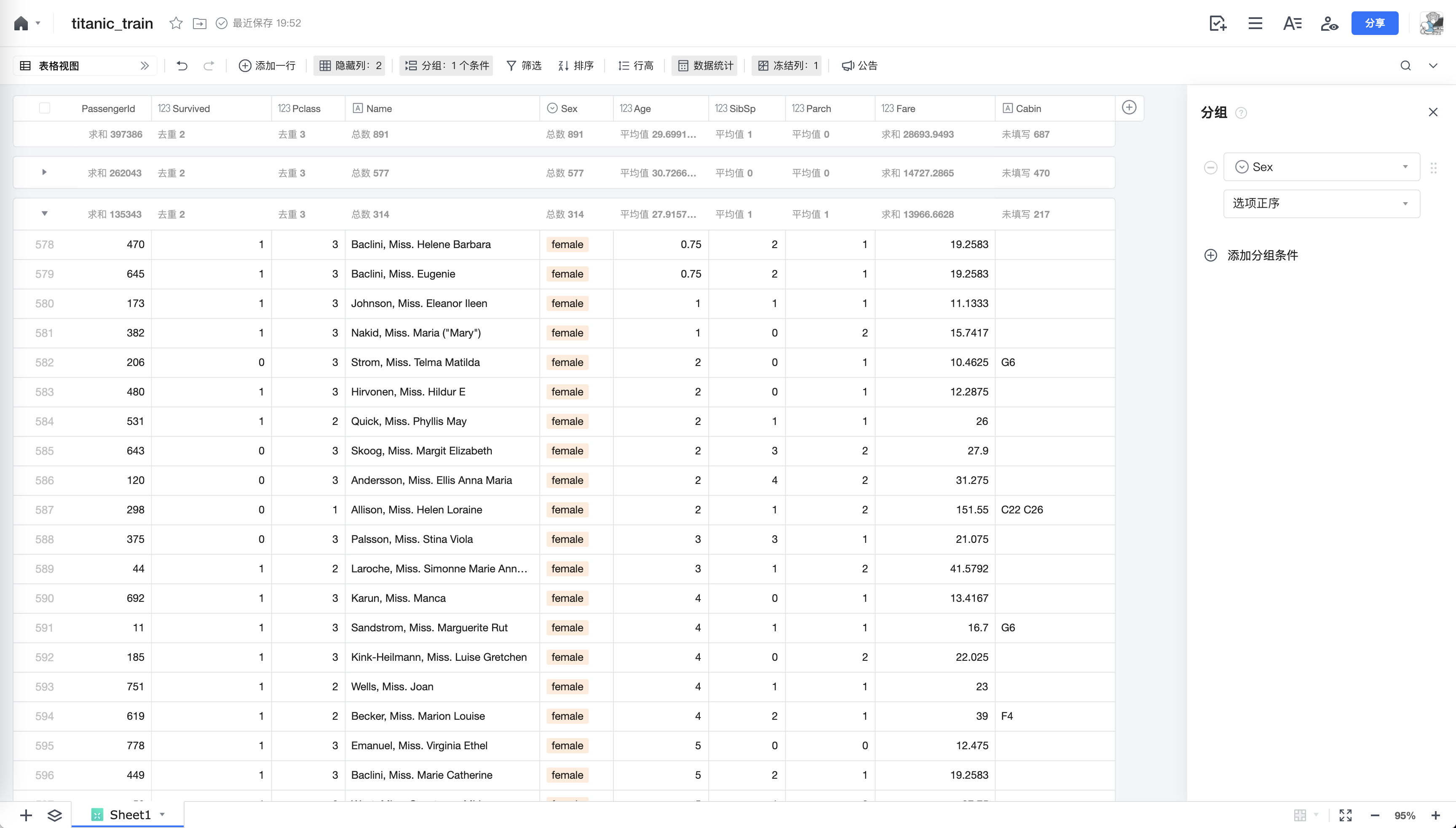
pandas中的分组功能和excel的逻辑有点差异,不能够同时进行汇总或者求均值,可以先统计:
|
|

- 存活下来的人总票价要高出一截,也可以猜测富人存活率高一点
再求均值:
|
|

- 存活下来的人平均票价要高出一截,也可以猜测富人存活率高一点
我们还可以按照性别分类进行统计:
|
|

- 女性的均值大于0.5,可以说明女性的存活率会更高(分布偏向1)
小结
我们通过分析泰坦尼克的数据,像使用Excel一样使用了Pandas,学习了数据统计、筛选、排序等常用功能。
参考链接
文章作者 shawn
上次更新 2023-04-16