前文[一步一步实现web服务器]介绍过 历史对比法 : 对比代码的需求变化和版本历史,从而学习需求如何被实现。今天我们一起从 requests 源码开始,使用 历史对比法,深入其实现细节,考古一下远古爬虫的实现。本文主要包括下面几个部分:
- 如何使用vs-code进行历史对比
- 如何使用pycharm-ce进行历史对比
- v0.2.1 文件上传支持
- v0.2.2 cookie支持
- v0.2.3 response优化
- v0.2.4 改进request类
- 小结
- 小技巧
如何使用vs-code git历史对比
工欲善其事,必先利其器,我们先花点时间了解如何使用各种IDE工具进行git历史对比操作。先是vs-code中安装git-history插件:
对比前,先切换到初始的v0.2.0版本。然后进入插件视图,搜索v0.2.1:
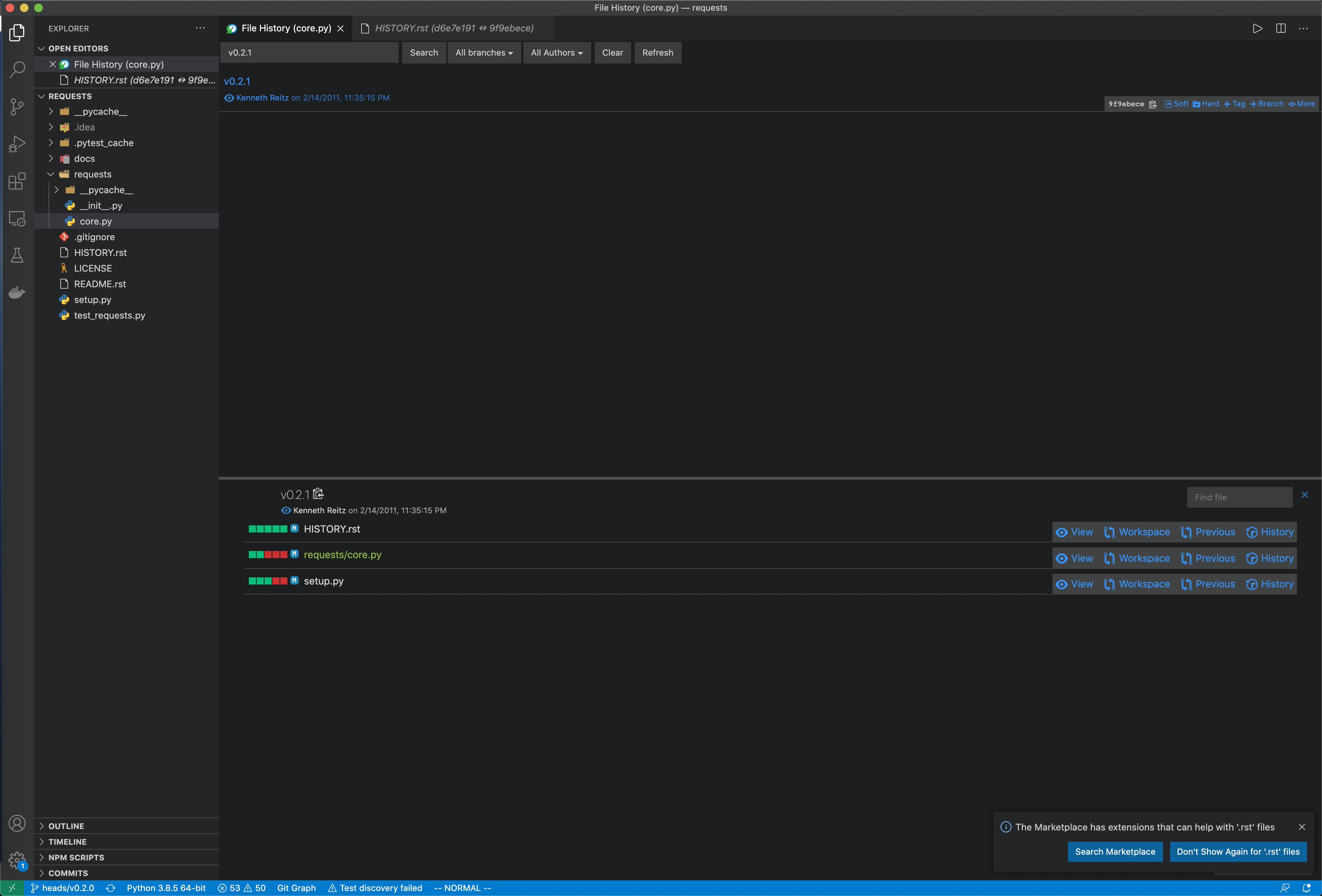
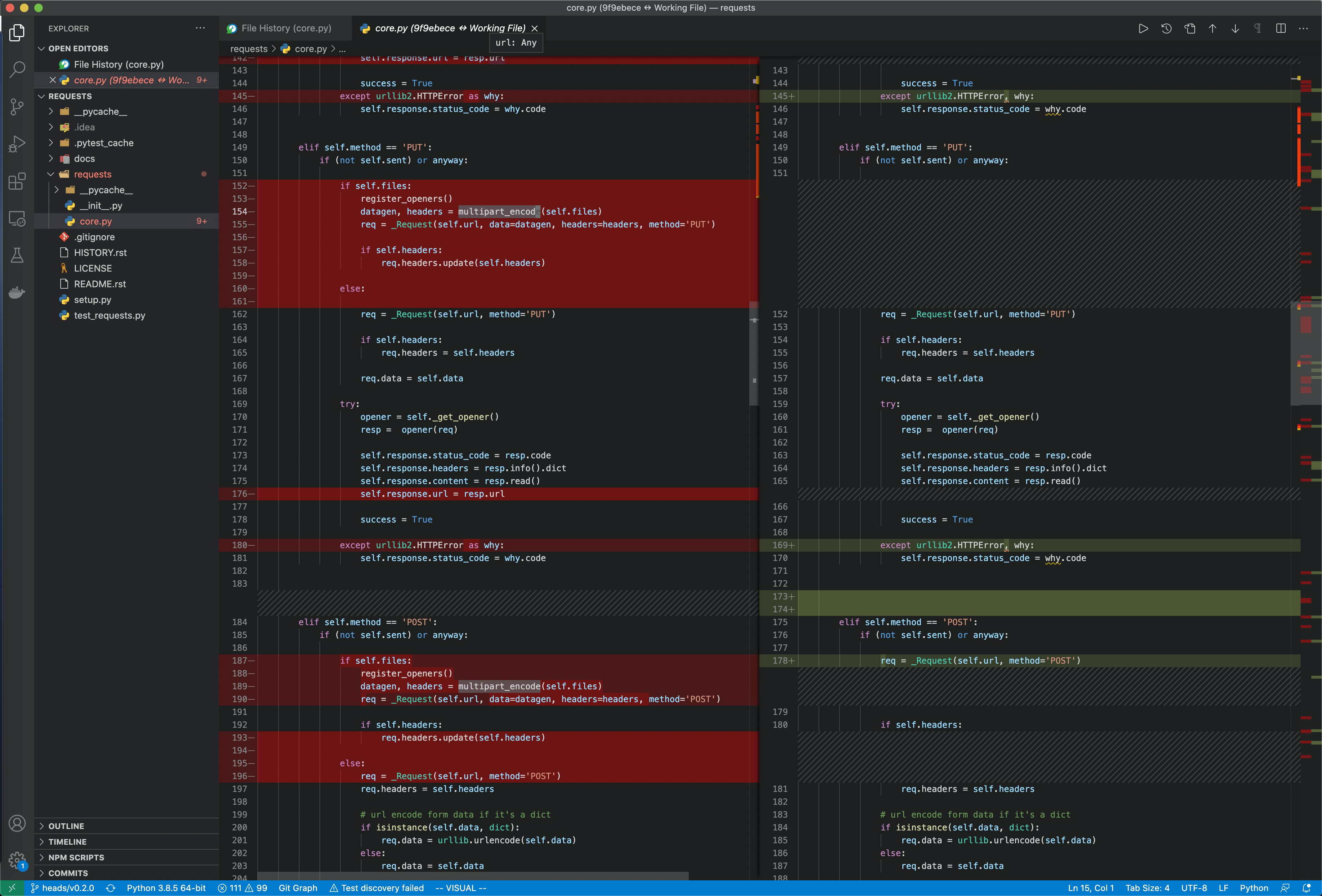
版本代码差异:
如何使用pycharm-ce git历史对比
pycharm的社区版本也支持git历史对比。同样进入git视图:
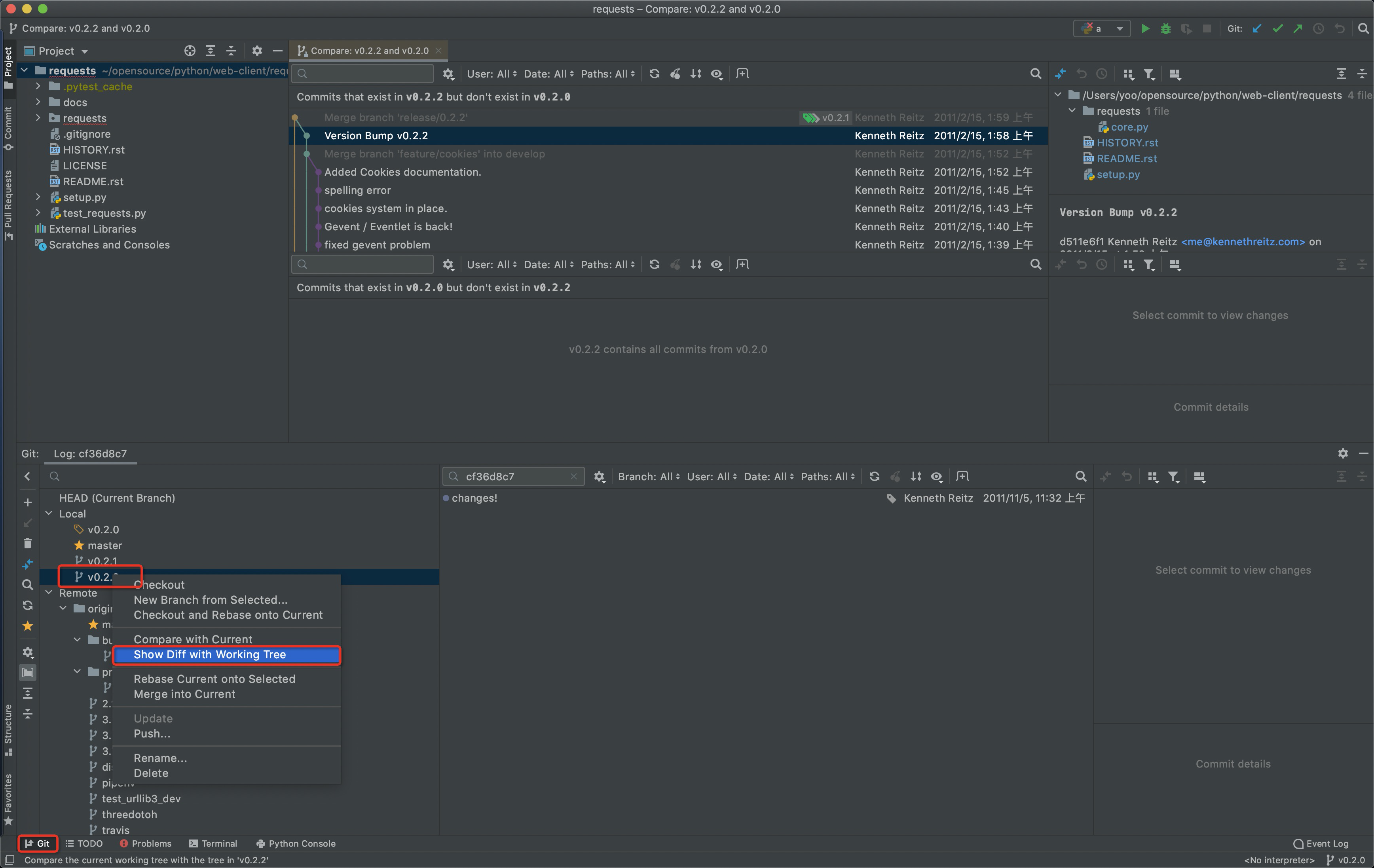
对比代码差异:
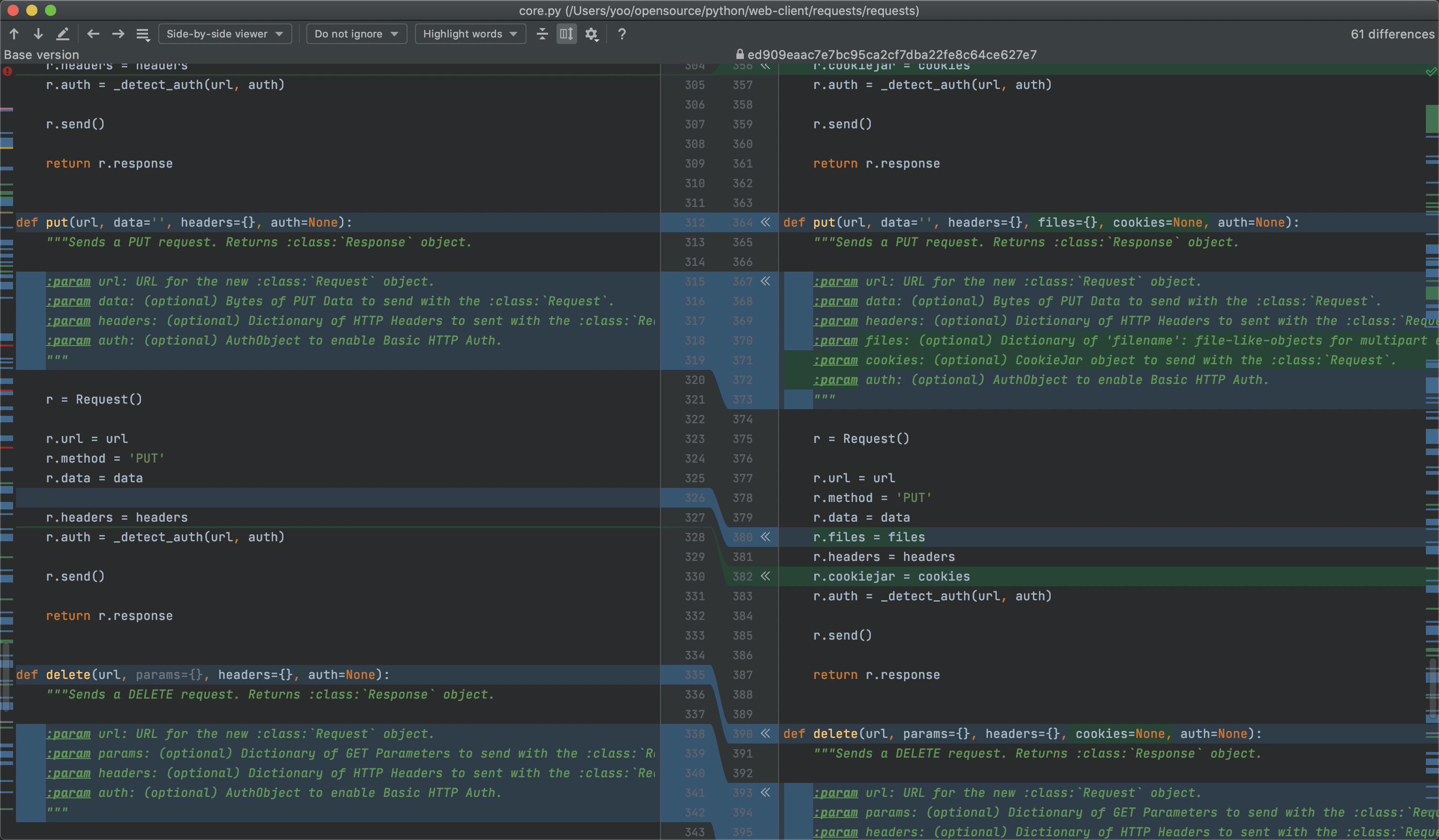
v0.2.1 文件上传支持
我们之前已经阅读过requests的代码,没有看过朋友可以去翻翻前文 requests 源码阅读 , 今天我们就略过v0.2.0的初始化版本介绍,直接进入对比分析。
HISTORY文件中介绍了v0.2.1新增的功能:
1
2
3
4
5
|
0.2.1 (2011-02-14)
++++++++++++++++++
* Added file attribute to POST and PUT requests for multipart-encode file uploads.
* Added Request.url attribute for context and redirects
|
文件上传功能涉及的代码主要是:
1
2
3
4
5
6
7
8
9
10
11
|
from .packages.poster.encode import multipart_encode
from .packages.poster.streaminghttp import register_openers
...
def send(self, anyway=False)
if self.method == 'POST':
if self.files:
register_openers() # 1
datagen, headers = multipart_encode(self.files) # 2
req = _Request(self.url, data=datagen, headers=headers, method='POST')
...
|
核心在register_openers和multipart_encode两行代码,一个是支持文件上传的连接,一个是支持文件数据读取。先看register_openers:
1
2
3
4
5
6
7
8
9
10
|
def register_openers():
handlers = [StreamingHTTPHandler, StreamingHTTPRedirectHandler]
if hasattr(httplib, "HTTPS"):
handlers.append(StreamingHTTPSHandler)
opener = urllib2.build_opener(*handlers)
urllib2.install_opener(opener)
return opener
|
主要在使用_StreamingHTTPMixin扩展了send方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class _StreamingHTTPMixin:
def send(self, value):
...
try:
if hasattr(value, 'next'):
for data in value:
self.sock.sendall(data)
...
except socket.error, v:
if v[0] == 32: # Broken pipe
self.close()
raise
|
可以看到send的支持从迭代器中读取并发送到socket。multipart_encode主要是读取本地文件并生成对于的http头:
1
2
3
4
5
6
|
def multipart_encode(params, boundary=None, cb=None)
boundary = gen_boundary()
boundary = urllib.quote_plus(boundary)
headers = get_headers(params, boundary)
params = MultipartParam.from_params(params)
return multipart_yielder(params, boundary, cb), headers
|
生成http头的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def get_headers(params, boundary):
"""Returns a dictionary with Content-Type and Content-Length headers
for the multipart/form-data encoding of ``params``."""
# boundary = uuid.uuid4().hex
headers = {}
boundary = urllib.quote_plus(boundary)
headers['Content-Type'] = "multipart/form-data; boundary=%s" % boundary
headers['Content-Length'] = str(get_body_size(params, boundary))
return headers
def get_body_size(params, boundary):
size = sum(p.get_size(boundary) for p in MultipartParam.from_params(params))
return size + len(boundary) + 6
|
boundary就是文件分段的分隔符,详情见: https://stackoverflow.com/questions/3508338/what-is-the-boundary-in-multipart-form-data
本地文件的读取准备主要在下面的iter_encode函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def iter_encode(self, boundary, blocksize=4096):
total = self.get_size(boundary)
current = 0
block = self.encode_hdr(boundary)
current += len(block)
yield block
last_block = ""
encoded_boundary = "--%s" % encode_and_quote(boundary)
boundary_exp = re.compile("^%s$" % re.escape(encoded_boundary),
re.M)
while True:
block = self.fileobj.read(blocksize)
if not block:
current += 2
yield "\r\n"
break
last_block += block
if boundary_exp.search(last_block):
raise ValueError("boundary found in file data")
last_block = last_block[-len(encoded_boundary)-2:]
current += len(block)
yield block
|
iter_encode函数将fileobj包装成一个迭代器返回,结合前面的send方法就实现了文件的http上传。
因为代码较少,我们还可以发现一些可以优化的代码, 比如下面的实现中MultipartParam.from_params执行了两次:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
def multipart_encode(params, boundary=None, cb=None):
...
headers = get_headers(params, boundary)
params = MultipartParam.from_params(params)
...
def get_body_size(params, boundary):
size = sum(p.get_size(boundary) for p in MultipartParam.from_params(params))
return size + len(boundary) + 6
def get_headers(params, boundary):
...
headers['Content-Length'] = str(get_body_size(params, boundary))
return headers
|
v0.2.2 cookie支持
v0.2.2主要功能是支持cookie:
1
2
3
4
5
6
|
0.2.2 (2011-02-14)
++++++++++++++++++
* Still handles request in the event of an HTTPError. (Issue #2)
* Eventlet and Gevent Monkeypatch support.
* Cookie Support (Issue #1)
|
比如put-API中,request对象上接收cookiejar
1
2
3
4
5
6
7
8
9
10
11
|
def put(url, data='', headers={}, files={}, cookies=None, auth=None):
r = Request()
r.url = url
r.method = 'PUT'
r.data = data
r.files = files
r.headers = headers
r.cookiejar = cookies
r.auth = _detect_auth(url, auth)
r.send()
return r.response
|
然后使用urllib2的HTTPCookieProcessor封装cookiejar
1
2
3
4
5
6
7
8
9
10
11
12
|
def _get_opener(self):
_handlers = []
if self.auth or self.cookiejar:
if self.cookiejar:
cookie_handler = urllib2.HTTPCookieProcessor(cookiejar)
_handlers.append(cookie_handler)
opener = urllib2.build_opener(*_handlers)
return opener.open
|
CookieJar的实现,就是在http头上增加Cookie字段,字段的值是一个字典序列化的字符串:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
class CookieJar:
def __init__(self, policy=None):
if policy is None:
policy = DefaultCookiePolicy()
self._policy = policy
self._cookies_lock = _threading.RLock()
self._cookies = {}
def add_cookie_header(self, request):
self._cookies_lock.acquire()
try:
self._policy._now = self._now = int(time.time())
cookies = self._cookies_for_request(request)
attrs = self._cookie_attrs(cookies)
if attrs:
if not request.has_header("Cookie"):
request.add_unredirected_header(
"Cookie", "; ".join(attrs))
# if necessary, advertise that we know RFC 2965
if (self._policy.rfc2965 and not self._policy.hide_cookie2 and
not request.has_header("Cookie2")):
for cookie in cookies:
if cookie.version != 1:
request.add_unredirected_header("Cookie2", '$Version="1"')
break
finally:
self._cookies_lock.release()
self.clear_expired_cookies()
|
配合下面cookie的示例,就很容易理解了:
1
|
Cookie: lang=zh-CN; i_like_gogs=a333326706d3bb1c; _csrf=KSQKMtYni1y4Zbi5aRpjYbW32t86MTYxNzY3NjIzNzg5MDg3NDY0MQ%3D%3D
|
同时代码进行了优化,增加了_build_response用来构建响应:
1
2
3
4
5
6
7
|
def _build_response(self, resp):
"""Build internal Response object from given response."""
self.response.status_code = resp.code
self.response.headers = resp.info().dict
self.response.content = resp.read()
self.response.url = resp.url
|
优化前后对比很明显:
1
2
3
4
5
6
7
8
9
10
11
|
# before
resp = opener(req)
self.response.status_code = resp.code
self.response.headers = resp.info().dict
if self.method == 'GET':
self.response.content = resp.read()
self.response.url = resp.url
# after
resp = opener(req)
self._build_response(resp)
|
我们可以认为这个优化符合DRY(Don’t repeat yourself)规则和迪米特法则LOD(Law of Demeter)。之前在V0.2.1中response的处理,GET,POST,PUT3个分支中重复;同时send函数还需要关心response的处理细节,重构后很好的解决了这2个问题。
v0.2.3 response优化
v0.2.3主要功能是response优化:
1
2
3
4
5
6
7
8
|
0.2.3 (2011-02-15)
++++++++++++++++++
* New HTTPHandling Methods
- Reponse.__nonzero__ (false if bad HTTP Status)
- Response.ok (True if expected HTTP Status)
- Response.error (Logged HTTPError if bad HTTP Status)
- Reponse.raise_for_status() (Raises stored HTTPError
|
response增加了一个ok状态,用来描述请求成功与否:
1
2
3
4
5
6
7
8
9
|
class Response(object)
def __init__(self):
self.content = None
self.status_code = None
self.headers = dict()
self.url = None
self.ok = False
self.error = None
|
同样response更加内聚,可以反应出请求的成功和失败:
1
2
3
4
5
6
7
8
9
|
# before
resp = opener(req)
self._build_response(resp)
success = True
# after
resp = opener(req)
self._build_response(resp)
self.response.ok = True
|
同时response还支持bool判断
1
2
3
|
def __nonzero__(self):
"""Returns true if status_code is 'OK'."""
return not self.error
|
__nonzero__为python的魔法函数
1
2
3
4
5
6
|
object.__nonzero__(self)
Called to implement truth value testing and the built-in operation bool();
should return False or True, or their integer equivalents 0 or 1. When this
method is not defined, __len__() is called, if it is defined, and the object
is considered true if its result is nonzero. If a class defines neither
__len__() nor __nonzero__(), all its instances are considered true.
|
详细链接: https://docs.python.org/2/reference/datamodel.html
v0.2.4 改进request类
v0.2.4主要工作是改进Request:
1
2
3
4
5
6
7
|
0.2.4 (2011-02-15)
++++++++++++++++++
* Python 2.5 Support
* PyPy-c v1.4 Support
* Auto-Authentication tests
* Improved Request object constructor
|
request改进了构造函数,支持更多参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class Request(object):
def __init__(self, url=None, headers=dict(), files=None, method=None,
params=dict(), data=dict(), auth=None, cookiejar=None):
self.url = url
self.headers = headers
self.files = files
self.method = method
self.params = params
self.data = data
self.response = Response()
self.auth = auth
self.cookiejar = cookiejar
self.sent = False
|
这样使用的时候:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# before
r = Request()
r.method = 'HEAD'
r.url = url
# return response object
r.params = params
r.headers = headers
r.cookiejar = cookies
r.auth = _detect_auth(url, auth)
r.send()
# after
r = Request(method='HEAD', url=url, params=params, headers=headers,
cookiejar=cookies, auth=_detect_auth(url, auth))
r.send()
|
另外重用认证信息,对于同一个url使用缓存中的url
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def add_autoauth(url, authobject):
global AUTOAUTHS
AUTOAUTHS.append((url, authobject))
def _detect_auth(url, auth):
return _get_autoauth(url) if not auth else auth
def _get_autoauth(url):
for (autoauth_url, auth) in AUTOAUTHS:
if autoauth_url in url:
return auth
return None
|
我们可以思考,认证按照url进行处理并不太好,按照domain可能更合适。
小结
通过v0.2.0~v0.2.4四个版本的源码历史对比法阅读,我们可以知道下面2个功能的实现逻辑:
- 文件上传的功能就是将本地文件读取到流中再通过socket发送出去
- cookie是在http头中的一个特殊序列化的字典
同时也了解了Reqeust和Response两个关键对象的一些优化方法,提高代码可读性的同时,也增加代码稳定性。
历史对比的同时,我们还可以发现一些有趣的题外细节。比如在2011-02-14~2011-02-15日两天,作者Kenneth Reitz完成了4个小版本的提交,果然是单身狗的快乐。
比较一下代码第一个版本的API:
1
2
3
4
|
>>> import requests
>>> r = requests.get('http://google.com')
>>> r.status_code
401
|
下面是现在的API:
1
2
3
|
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
|
可以看到长达10年的时间内,作者最开始设计的API基本没有变化,这个还是挺厉害的。
小技巧
应该避免使用硬编码的魔法数字,比如在v0.2.1中的get_body_size:
1
2
3
|
def get_body_size(params, boundary):
size = sum(p.get_size(boundary) for p in MultipartParam.from_params(params))
return size + len(boundary) + 6
|
这里的数字6就比较难以理解。
没错,反例也是技巧 :)
参考链接