本章我们从celery的设计工作流程来了解分布式任务的实现。
Celery是一款非常简单、灵活、可靠的分布式系统,可用于处理大量消息,并且提供了一整套操作此系统的工具。Celery 也是一款消息队列工具,可用于处理实时数据以及任务调度。
本文是是celery源码解析的第八篇,在前七篇里分别介绍了:
- 神器 celery 源码解析- vine实现Promise功能
- 神器 celery 源码解析- py-amqp实现AMQP协议
- 神器 celery 源码解析- kombu,一个python实现的消息库
- 神器 celery 源码解析- kombu的企业级算法
- 神器 celery 源码解析- celery启动流程分析
- 神器 celery 源码解析- celery启动日志跟踪
- 神器 celery 源码解析- 蓝图分析
基础概念
日常生活中一个大型的任务,我们一般都会进行拆分,变成若干小任务;为了提高处理效率,缩短任务的执行时间,我们还会将没有依赖关系的任务并行推进,最后再把所有分支任务进行汇总。
celery作为一个分布式任务系统,也是这样设计其工作流的。在开始之前我们先看看其中几个基础概念。
高阶函数(Map, Filter and Reduce)
python中提供了3个高阶函数: map, filter和reduce,可以对数据(任务)进行批处理。下面是map函数:
1
2
3
4
5
|
items = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, items))
print(squared)
# output: [1, 4, 9, 16, 25]
|
可以看到使用map函数对目标列表[1, 2, 3, 4, 5]的每一个元素,执行了一次平方操作,并且返回一个新的结果列表[1, 4, 9, 16, 25]。使用map函数,比我们使用for循环实现要简洁。
filter函数和map类似,区别在于对目标列表的每个元素执行一次条件过滤判断,符合要求的数据才会保存到结果列表:
1
2
3
4
5
|
number_list = range(-5, 5)
less_than_zero = list(filter(lambda x: x < 0, number_list))
print(less_than_zero)
# Output: [-5, -4, -3, -2, -1]
|
reduce函数则是对目标列表依次执行函数并且进行累积:
1
2
3
4
5
|
from functools import reduce
# 1*2*3*4=24
product = reduce((lambda x, y: x * y), [1, 2, 3, 4])
# Output: 24
|
大数据中的MapReduce也是这样的思路,把大量的数据分成多个块,分别计算,最后再把结果汇总:
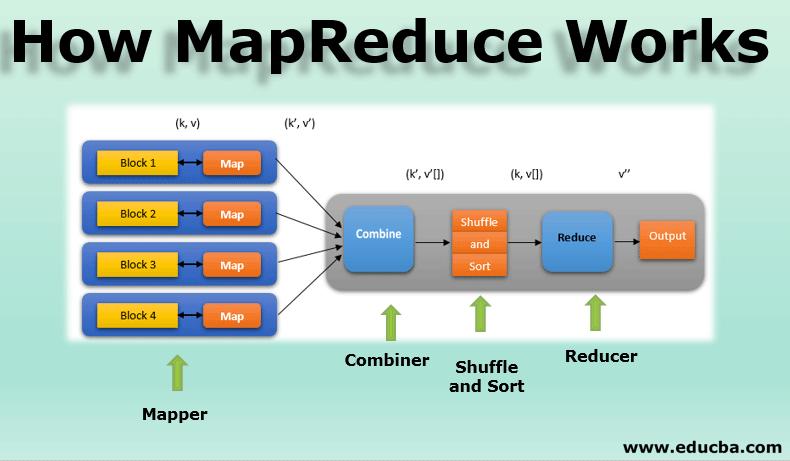
管道模型(pipeline)
管道模型,大家应该都不陌生。比如linux系统中使用管道符 | ,用下面命令快速查找 nginx的进程:
在我之前的requests源码解析文章中,也介绍过hook系统使用管道模型,可以把多个钩子串行化处理:
1
2
3
4
5
6
7
8
9
|
def dispatch_hook(key, hooks, hook_data, **kwargs):
"""Dispatches a hook dictionary on a given piece of data."""
...
for hook in hooks:
_hook_data = hook(hook_data, **kwargs)
if _hook_data is not None:
hook_data = _hook_data
...
return hook_data
|
dispatch_hook函数中:
- 每个hook接收hook_data数据并返回一个hook_data数据
- 前一个hook的返回值会当做下一个hook的参数
柯里化(Currying)
柯里化(Currying)是一种关于函数的高阶技术, 柯里化是一种函数的转换,它是指将一个函数从可调用的 f(a, b, c) 转换为可调用的 f(a)(b)(c)。柯里化不会调用函数。它只是对函数进行转换。下面是js版本示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
function curry(f) { // curry(f) 执行柯里化转换
return function(a) {
return function(b) {
return f(a, b);
};
};
}
// 用法
function sum(a, b) {
return a + b;
}
let curriedSum = curry(sum);
alert( curriedSum(1)(2) ); // 3
|
- sum函数的两个参数,通过柯里化的处理方式,变成了2个匿名函数
- 每次函数的调用会传递1个参数并返回一个新函数,直到执行完成
部分函数(partial)
在python中partial()会被“冻结了”一部分函数参数和/或关键字的部分函数应用所使用,从而得到一个具有简化签名的新对象,和柯里化很类似。下面是示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from functools import partial
# A normal function
def f(a, b, c, x):
return 1000*a + 100*b + 10*c + x
# A partial function that calls f with
# a as 3, b as 1 and c as 4.
g = partial(f, 3, 1, 4)
# Calling g()
print(g(5))
print(g(6))
|
- 通过partial将f函数的4个参数分成2个部分传入
- 先传入3,1,4得到一个函数g
- 使用g可以用来反复用计算x的值
currying和partial都是利用了闭包的特性,将函数的部分参数临时缓存住,从而达到重用函数的目的。
celery工作流(workflow)示例
签名(Signatures)
签名可以把任务使用函数签名的方式进行调用,这样可以让任务的生产者和消费者进行解耦。这样介绍有点泛泛,还是看一看其具体的使用过程, 我们先使用celery -A myapp worker -l DEBUG启动我们的测试worker ,然后新开一个python3的shell:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
✗ python3
Python 3.8.5 (v3.8.5:580fbb018f, Jul 20 2020, 12:11:27)
[Clang 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from celery import Celery
>>> app = Celery(
... 'myapp',
... broker='redis://localhost:6379/0',
... result_backend='redis://localhost:6379/0',
... # ## add result backend here if needed.
... backend='rpc'
... )
>>>
|
在新的shell中我们需要创建celery的app,然后使用signature方式创建一个task:
1
2
|
>>> from celery import signature
>>> t = signature('myapp.add', args=(2, 2), countdown=10)
|
这个签名包括了任务的名称是 myapp.add, 2个参数,超时时间设置为10s。使用task的apply_async函数获取到AsyncResult结果:
1
2
3
|
>>> r = t.apply_async()
>>> r.get()
4
|
观测worker的日志也可以看到myapp.add被远程执行。
本地(进程)是没有add这个任务函数的,可以使用下面方式校验,直接执行t任务会报错:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
>>> t()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/yoo/work/yuanmahui/python/.venv/lib/python3.8/site-packages/celery/canvas.py", line 174, in __call__
return self.type(*args, **kwargs)
File "/Users/yoo/work/yuanmahui/python/.venv/lib/python3.8/site-packages/kombu/utils/objects.py", line 29, in __get__
return super().__get__(instance, owner)
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/functools.py", line 967, in __get__
val = self.func(instance)
File "/Users/yoo/work/yuanmahui/python/.venv/lib/python3.8/site-packages/celery/canvas.py", line 505, in type
return self._type or self.app.tasks[self['task']]
File "/Users/yoo/work/yuanmahui/python/.venv/lib/python3.8/site-packages/celery/app/registry.py", line 18, in __missing__
raise self.NotRegistered(key)
celery.exceptions.NotRegistered: 'myapp.add'
|
上面就是signature的示例。这样我们的任务系统就可以脱离web服务的实现,仅提供任务函数的签名,也就是任务名称和参数要求。在web服务中要执行任务只需要使用这个函数签名进行调用。web服务和celery任务解耦后,让代码维护更容易维护。
signature还提供了快捷方式, 可以从task创建:
1
2
3
4
|
>>> add.signature((2, 2), countdown=10)
tasks.add(2, 2)
>>> add.s(2, 2)
tasks.add(2, 2)
|
原语(Primitive)
celery提供了一系列的组合任务执行的方法函数,叫做原语(Primitives),主要包括:
- group 可以并行处理的一组任务
- chain 将任务组装成一个调用链
- chord 可以使用Map-Reduce的方式执行任务
- map 使用map方式执行系列任务
- starmap 类似map方式,支持*args
- chunks 将任务拆分成块进行执行
我们重点看一看chain,chord和chunks三种方式的示例。
下面是chain方式:
1
2
3
4
5
6
|
>>> from celery import chain
>>> # 2 + 2 + 4 + 8
>>> res = chain(add.s(2, 2), add.s(4), add.s(8))()
>>> res.get()
16
|
可以看到3个add任务使用chain关键字串联起来,前面函数的结果是后面函数的参数。第一个add使用了2个参数2+2, 第二/三个add则只有一个参数。chain还可以使用管道方式创建:
1
2
3
|
>>> res = (add.si(2, 2) | add.si(4, 4) | add.si(8, 8))()
>>> res.get()
16
|
chord(和弦)的示例如下:
1
2
3
4
|
>>> from celery import chord
>>> res = chord((add.s(i, i) for i in range(10)), xsum.s())()
>>> res.get()
90
|
- chord 需要提供2个参数,第一个是任务列表,这种分步任务叫做header-task,第二个是汇总任务叫做body-task
- 任务提交后会先执行每个header-task,最后再把这些header-task的结果使用body-task汇总
chunks的示例:
1
2
|
>>> items = zip(range(1000), range(1000)) # 1000 items
>>> add.chunks(items, 10)
|
先复习一下zip函数的逻辑:
1
2
3
4
5
6
7
|
languages = ['Java', 'Python', 'JavaScript']
versions = [14, 3, 6]
result = zip(languages, versions)
print(list(result))
# Output: [('Java', 14), ('Python', 3), ('JavaScript', 6)]
|
可以看到zip把两个列表合并形成一个二维数组,就像拉链一样。上面的add.chunks就是把1000个元素的二维数组,逐一执行一下add函数,执行过程分成10个块,这样会产生100个任务。使用chunks可以批量生成的系列任务。
回头再看 原语,简单的理解就是把一系列复杂的逻辑操作抽象封装成一个单一的操作(函数),提供一个唯一的关键字。
canvas模块实现
了解了celery-workflow的基础知识和示例后,我们继续深入了解它是如何实现的。主要实现都在canvas模块,其类结构大概如下:
1
2
3
4
5
6
7
8
9
10
|
+-----------+
| Signature |
+------^----+
|
+------------+-------------+-------------+----------+--------------+
| | | | | |
| | | | | |
+-----+-+ +----+---+ +-------+ +----+--+ +--+---+ +-----+----+
| chain | | chunks | | group | | chord | | xmap | | xstarmap |
+-------+ +--------+ +-------+ +-------+ +------+ +----------+
|
因为所有的原语都继承自Signature类,我们从Signature开始:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class Signature(dict):
def __init__(self, task=None, args=None, kwargs=None, options=None,
type=None, subtask_type=None, immutable=False,
app=None, **ex):
self._app = app
try:
# task
task_name = task.name
except AttributeError:
# 字符串
task_name = task
else:
self._type = task
# self['task']
super().__init__(
task=task_name, args=tuple(args or ()),
kwargs=kwargs or {},
options=dict(options or {}, **ex),
subtask_type=subtask_type,
immutable=immutable,
chord_size=None,
)
|
Signature继承自dict,主要的key是:task,就是任务的名称;args和kwargs,执行任务的参数;options,前面的选项。重点是signature关联app,这个后面会用来执行任务。
执行任务使用apply_async:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def apply_async(self, args=None, kwargs=None, route_name=None, **options):
args = args if args else ()
kwargs = kwargs if kwargs else {}
# Extra options set to None are dismissed
options = {k: v for k, v in options.items() if v is not None}
try:
_apply = self._apply_async
except IndexError: # pragma: no cover
# no tasks for chain, etc to find type
return
# For callbacks: extra args are prepended to the stored args.
if args or kwargs or options:
# 合并参数
args, kwargs, options = self._merge(args, kwargs, options)
else:
args, kwargs, options = self.args, self.kwargs, self.options
# pylint: disable=too-many-function-args
# Borks on this, as it's a property
return _apply(args, kwargs, **options)
|
apply_async执行任务的时候,还可以继续传入参数,传入的参数会和signature的参数进行合并,这就为chain提供了基础。创建signature时候提供一部分参数,执行的时候再提供一部分参数。任务的具体执行,实际上使用的是app的send_task方法,因为每个signature的task_name都是一样的,所以这里使用了partial的方式:
1
2
3
4
5
6
|
def _apply_async(self):
try:
return self.type.apply_async
except KeyError:
# 使用app的send_task发送任务
return _partial(self.app.send_task, self['task'])
|
signature实际上就是task的一种包装,比较特别的是它还可以使用 | 进行按位或运算,模拟管道的执行,比如:
1
2
3
|
>>> res = (add.si(2, 2) | add.si(4, 4) | add.si(8, 8))()
>>> res.get()
16
|
这个功能的是因为signature使用了元编程,覆盖了__or__函数, 其部分实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def __or__(self, other):
# These could be implemented in each individual class,
# I'm sure, but for now we have this.
...
elif isinstance(other, Signature):
if isinstance(self, _chain):
...
# chain | task -> chain
return _chain(seq_concat_item(
self.unchain_tasks(), other), app=self._app)
# task | task -> chain
return _chain(self, other, app=self._app)
return NotImplemented
|
这个过程大概分成2步:
- 第一步add.si(2, 2) | add.si(4, 4) 是上是task | task,这时候会返回一个chain
- 第二步是chain和add.si(8, 8)这样的task进行按位或,会继续返回一个chain
__or__函数中同样提供了group类型,chord类型的实现,原理类似。我们继续查看chain的实现:
1
2
3
4
5
6
7
8
9
|
class chain(_chain):
def __new__(cls, *tasks, **kwargs):
# This forces `chain(X, Y, Z)` to work the same way as `X | Y | Z`
if not kwargs and tasks:
if len(tasks) != 1 or is_list(tasks[0]):
tasks = tasks[0] if len(tasks) == 1 else tasks
return reduce(operator.or_, tasks, chain())
return super().__new__(cls, *tasks, **kwargs)
|
从注释可以理解chain(X, Y, Z),本质上就是X | Y | Z,通过reduce函数实现。
然后我们在跟踪一下第一个task的结果如何传递给第二个task主要在run函数和prepare_steps中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
def run(self, args=None, kwargs=None, group_id=None, chord=None,
task_id=None, link=None, link_error=None, publisher=None,
producer=None, root_id=None, parent_id=None, app=None, **options):
...
tasks, results_from_prepare = self.prepare_steps(
args, kwargs, self.tasks, root_id, parent_id, link_error, app,
task_id, group_id, chord,
)
...
if results_from_prepare:
first_task = tasks.pop()
options = _prepare_chain_from_options(options, tasks, use_link)
# 执行第一个任务
result_from_apply = first_task.apply_async(**options)
if not tasks:
return result_from_apply
else:
# 依次返回下一个任务
return results_from_prepare[0]
def prepare_steps(self, args, kwargs, tasks,
root_id=None, parent_id=None, link_error=None, app=None,
last_task_id=None, group_id=None, chord_body=None,
clone=True, from_dict=Signature.from_dict,
group_index=None):
steps = deque(tasks)
prev_task = None
prev_res = None
tasks, results = [], []
i = 0
while steps:
...
task = steps_pop()
res = task.freeze(root_id=root_id)
...
# 把任务的结果串起来
if prev_res and not prev_res.parent:
prev_res.parent = res
...
tasks.append(task)
results.append(res)
...
return tasks, results
|
为什么每个task可以串起来呢,是因为freeze函数返回AsyncResult, 而AsyncResult是vine的promise,所以可以串起来执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
def freeze(self, _id=None, group_id=None, chord=None,
root_id=None, parent_id=None, group_index=None):
opts = self.options
try:
tid = opts['task_id']
except KeyError:
tid = opts['task_id'] = _id or uuid()
if root_id:
opts['root_id'] = root_id
if parent_id:
opts['parent_id'] = parent_id
...
return self.AsyncResult(tid)
|
chord和chunks的实现和chain差不多,就不再赘述了。
小结
本文我们了解了一些批量处理任务的方法:map/filter/reduce/pipeline。了解对函数进行partial和curry处理,都是利用闭包机制,提高函数的重用性。celery利用这些机制,提供了一些便捷使用的原语: chain, chord, chunks … , 帮助应用组合和拆分任务构建任务的工作流,提高效率。同时celery作为一个分布式任务系统,也可以使用任务签名Signature的方式进行任务调用,将任务的生产者和消费者分离,降低系统耦合度,这对大型系统非常有用。
我们通过对celery的了解,相信大家对 分布式系统 有初步的认识,建立了一些 索引 ,需要研究的时候,会知道在那些地方进行深入的学习,我想这就达到了预期目的。
一点题外话: celery的源码解析是9月份开始,当时预计3~4篇,结果没有想到写了8篇,持续4个月。由于能力和精力有限,一些内容没有解析的很细致,不过还是打算暂时完结,本篇是系列的最后一篇。未到位的地方,以后有机会再补充。感谢大家付出的时间!
参考链接